Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Everyday I take subway to my office, where my cellphone has no signal at all. But medium app won’t let me read stories offline, so I decided to make a news scraper by myself.
I didn’t want to make a very fancy application so I only completed the minimal prototype that can satisfy my needs. The concept is very simple:
- Find some news source
- Scrape the news page with Python
- Parse the html and extract the content with BeautifulSoup
- Convert it to readable format then send an E-mail to myself
Now let me explain how I did each part.
News Source: Reddit
People submit links to Reddit and vote them, so Reddit is a good news source to read news. Now the problem is: How to get a list of popular news everyday?
Before thinking of web scraping, we should try to find out whether the target website provides any API, since using API is completely legit, and most importantly, API provides machine readable data so we don’t need to parse HTML.
Fortunately Reddit provides API. From its API list we can easily find what we need: /top. This endpoint will return the top news on Reddit or given subreddit. So that we can use it to retrieve top news from our interested subreddits.
The next question is: How could we access this API?
After reading Reddit documentation I found the best way of accessing this endpoint.
The first step is to create an application on Reddit. Login to my account and go to “preferences → apps”. At the bottom there is a button called “create another app…”. Click it and create a “script” type application. Note we don’t need to provide “about url” or “redirect url” since our application does not intend to be accessed publicly or by anyone else.
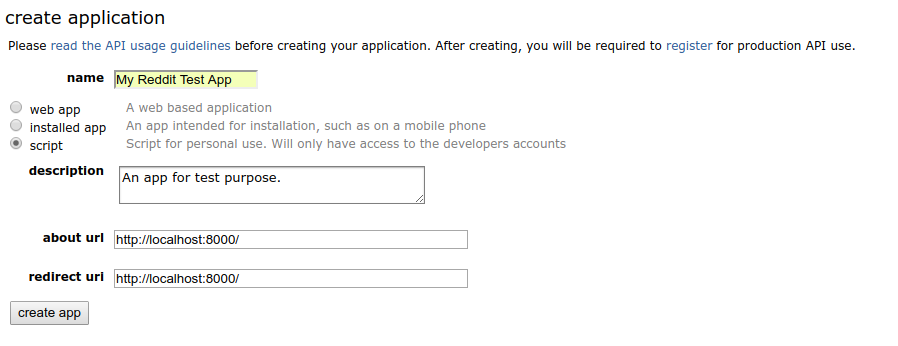
After the app is created, we could find the app id and secret in the app info box.
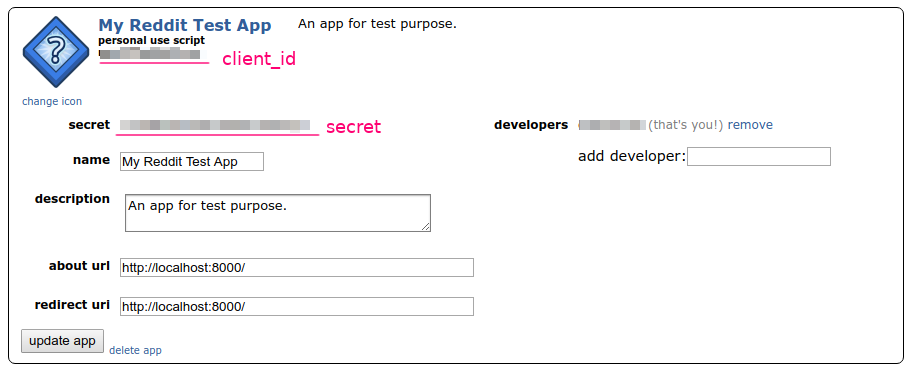
The next question is how to use this credential. Since we only need to fetch the top news of given subreddit, we don’t need to access any user related information, so technically we don’t need to provide any user information, like username or password. Reddit provides “Application Only OAuth” by which our app can access public information anonymously. Try the following command to test the API:
$ curl -X POST -H 'User-Agent: myawesomeapp/1.0' -d grant_type=client_credentials --user 'OUR_CLIENT_ID:OUR_CLIENT_SECRET' https://www.reddit.com/api/v1/access_token
We will get the access token like this:
{"access_token": "ABCDEFabcdef0123456789", "token_type": "bearer", "expires_in": 3600, "scope": "*"}Excellent! With the access token we can do anything.
The last thing, we don’t want to write the API access code from scratch. We can use the python client library:
Let’s do a quick test. We fetch the top 5 submissions from /r/Python:
>>> import praw>>> import pprint>>> reddit = praw.Reddit(client_id='OUR_CLIENT_ID',... client_secret='OUR_SECRET',... grant_type='client_credentials',... user_agent='mytestscript/1.0')>>> subs = reddit.subreddit('Python').top(limit=5)>>> pprint.pprint([(s.score, s.title) for s in subs])[(6555, 'Automate the boring stuff with python - tinder'), (4548, 'MS is considering official Python integration with Excel, and is asking for ' 'input'), (4102, 'Python Cheet Sheet for begineers'), (3285, 'We started late, but we managed to leave Python footprint on r/place!'), (2899, "Python Section at Foyle's, London")]Great!
Scrape the News Page
The next step is fairly simple. From last step, we could get the Submission object, whose url attribute is exactly the URL we want. We could also filter the URLs by checking domain attribute to make sure we only scrape links from websites other than Reddit.
subs = [sub for sub in subs if not sub.domain.startswith('self.')]All we need to do next is to fetch the URL. This can be done with requests:
for sub in subs: res = requests.get(sub.url) if (res.status_code == 200 and 'content-type' in res.headers and res.headers.get('content-type').startswith('text/html')): html = res.textHere we skipped the submissions whose content type is not text/html. This is because users may submit direct image links which are not our target.
Extract the Content
The next step is to extract the text content from the news HTML. Our goal is to extract the news title and news content, and ignore things like page header, footer, sidebar or anything we don’t need to read.
This is a pretty hard task and honestly there are no universal, perfect solution. We can use BeautifulSoup to extract the text content, but it will extract everything including the header and footer.
I was lucky enough to find that modern websites are created very well-formatted than their ancestors. We no longer see table layouts and <font>s and <br>s, instead, the article page is clearly marked with <h1>for title and <p> for each paragraph. I found that most website will put the title and main content in the same container element, for example:
<header>Site Navigation</header><div id="#main"> <section> <h1 class="title">Page Title</h1> </section> <section> <p>Paragraph 1</p> <p>Paragraph 2</p> </section></div><aside>Sidebar</aside><footer>Copyright...</footer>
Here the top level <div id="#main"> is a common container for both title and content. So we could make an algorithm to find the content:
- Find <h1> as the title. Usually there is only one <h1> in the page, for the purpose of SEO.
- Find the parent of <h1> and test if the parent has enough <p> elements.
- Repeat step 2 until a parent element with enough <p> elements are found or <body> tag is reached. If enough <p> are found, then the parent element is the main content tag. If <body> tag reached before enough <p> are found, then the page does not contain readable content.
This is a simple algorithm and did not consider any semantic information, but it actually works very well for our purpose. Anyway we can simply ignore the news if this algorithm fails, it does not hurt for me to read one less news…You could definitely make a more accurate algorithm by parsing the <header>, <footer>, or the #main, .sidebar id / classes.
With this algorithm we can easily write the parser code:
soup = BeautifulSoup(text, 'html.parser')
# find the article titleh1 = soup.body.find('h1')# find the common parent for <h1> and all <p>s.root = h1while root.name != 'body' and len(root.find_all('p')) < 5: root = root.parentif len(root.find_all('p')) < 5: return None# find all the content elements.ps = root.find_all(['h2', 'h3', 'h4', 'h5', 'h6', 'p', 'pre'])
Here we used len(root.find_all('p')) < 5 as the condition for main content, because a true news is less likely to have less than 5 paragraphs. You can increase this value for your needs.
Convert to Readable Format
The last step is to convert the content to readable format. I chose Markdown in this example but you can make your own fancy converter.
In this example I only fetched <h#> and <p>, <pre> so a quick function can convert these to Markdown easily.
ps = root.find_all(['h2', 'h3', 'h4', 'h5', 'h6', 'p', 'pre'])ps.insert(0, h1) # add the titlecontent = [tag2md(p) for p in ps]
def tag2md(tag): if tag.name == 'p': return tag.text elif tag.name == 'h1': return f'{tag.text}\n{"=" * len(tag.text)}' elif tag.name == 'h2': return f'{tag.text}\n{"-" * len(tag.text)}' elif tag.name in ['h3', 'h4', 'h5', 'h6']: return f'{"#" * int(tag.name[1:])} {tag.text}' elif tag.name == 'pre': return f'```\n{tag.text}\n```'Put Them Together
And finally here’s the complete code:
Exactly 100 lines! Try to run it…
Scraping /r/Python... - Retrieving https://imgs.xkcd.com/comics/python_environment.png x fail or not html - Retrieving https://thenextweb.com/dd/2017/04/24/universities-finally-realize-java-bad-introductory-programming-language/#.tnw_PLAz3rbJ => done, title = "Universities finally realize that Java is a bad introductory programming language" - Retrieving https://github.com/numpy/numpy/blob/master/doc/neps/dropping-python2.7-proposal.rst x fail or not html - Retrieving http://www.thedurkweb.com/sms-spoofing-with-python-for-good-and-evil/ => done, title = "SMS Spoofing with Python for Good and Evil" ...
And the scraped news:
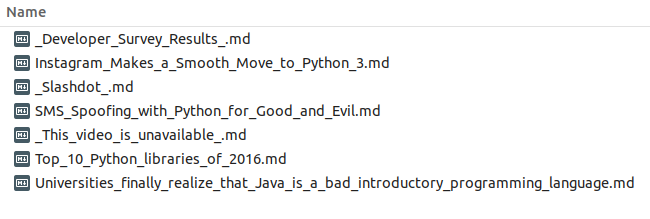
Then the last thing I need to do is to put this script on my server, setup a cron job to run it once a day, and send the generated files to my E-mail.
I didn’t put too many efforts to the detail so there are still many things that can be improved. You can keep adding more features to this script, such as making the result file more beautiful and extracting images.
Thanks for reading! Hopefully this script is useful, at least it could be an example for accessing Reddit API. Please recommend this post if you like it.
I Made a News Scraper with 100 Lines of Python. was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.