Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
AlphaRisk, Alipay’s 5th generation risk control engine increases the identification rate for cash-out fraud by 3x, with a combination of active learning and semi-supervised modeling

The development of mobile Internet and smartphones along with the rise of fintech has given way to one of the most transformative consumer-facing technologies today — mobile payments. Though adoption of mobile wallets has been slow moving in the United States, they are a way of life in China. A majority of transactions in Chinese cities are now cashless, with the volume between January-October 2017 reaching $12.8 trillion, more than 90 times the size of the mobile payments market in the U.S. Alipay, Ant Financial’s mobile wallet app, leads the Chinese market with a 54 percent market share of mobile payments.
The centrality of mobile payments in Chinese consumers’ lifestyles makes ensuring safety and reducing transaction risks a critical task. From the moment an Alipay user’s payment QR code is read by the scanner to the completion of payment less than a second later, Alipay’s risk control system performs numerous transaction scans verifying that the account has not been hijacked or misappropriated, and that the transaction is genuine in nature.
Alipay uses a state-of-the-art risk control engine named AlphaRisk, at the core of which lies AI Detect. As an intelligent risk identification algorithm system, AI Detect incorporates not just traditional supervised learning algorithms like Gradient Boosting Decision Tree (GBDT), but also a variety of feature generation algorithms based on unsupervised deep learning.
Tackling Illegal Cash-outs with AI Detect
The array of risks that accompany online transactions pose numerous challenges to modeling. Common concerns like stolen phones and identity thefts are usually easier to model under the supervised learning framework, while the construction of risk identification models for illegal cash-outs is usually more difficult. Cash-out risks lack an active external feedback mechanism, i.e., no black and white tags on samples. When users report stolen accounts or fraud, they also identify and report the transactions that are a result of such activity, which are then escalated further using historical data tags. However, users don’t report to Alipay or the bank which transactions are carried out for the purpose of cash-outs, much less those who do so illegally.
Common supervised algorithms are ineffective without tags. Hence, most cash-out risk identification systems rely on unsupervised models such as anomaly detection and graph algorithms. Though unsupervised models do not require tags, they aren’t the easiest to work with either. Anomaly detection models such as Isolation Forest require more effort on input features and perform inconsistently in terms of top scores if the number of features increases. Graph algorithms, on the other hand, often require massive computing power to effectively process the millions of daily Alipay transactions, translating into higher operational requirements and computational costs.

Manually labeling samples based on operating history followed by supervised learning based on labels is another option, but that too faces some trade-offs. Labeling costs run high, and on average, manually labeling each sample can take an engineer with the requisite knowledge anywhere from five to fifteen minutes. This makes it difficult to sample labels in large volumes. Labeling also incurs errors — humans are humans, and even the best of experts are prone to making mistakes in how they judge samples. Generally speaking, judging a sample to be black is easier since usually, some type of evidence follows the sample, but for a white sample, one must disqualify any evidence, something that is rather difficult to achieve in practice.
Faced with these issues, the Alibaba tech team devised an Active PU Learning method which combines active learning (referred to as AL), and Two-step Positive and Unlabeled Learning (referred to as PU), overcoming the issues posed by manual labeling while developing a distinct identification model for cash-out risks for credit card transactions. Even within the scope of the same accuracy requirements, the model returns a 3x improvement in the identification rate when compared to the baseline model using Isolation Forest.
Understanding Active PU Learning
Active learning
Active Learning is derived from a simple idea — if the cost per tag runs high, only those samples that have the highest improvement impact on the current algorithm should be labeled. This returns better results with lesser effort. The method assumes that a learner module actively interacts with the expert across multiple rounds and continuously updates the classifier based on the results returned by the expert labels.
The following figure demonstrates Active Learning’s basic workflow.
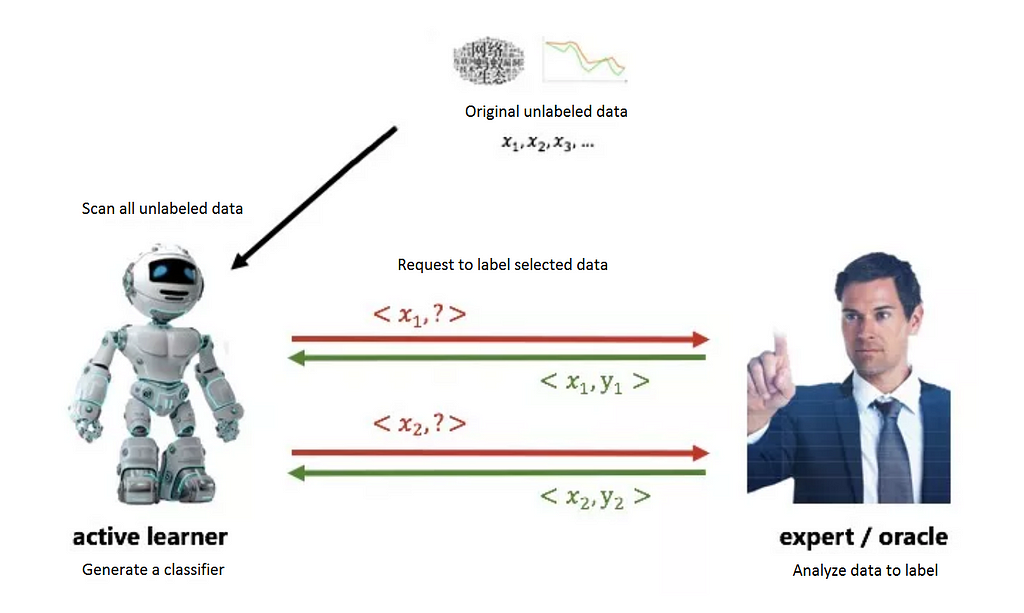 Active learning workflow
Active learning workflow
PU learning
AL by itself does not limit the specific ways to generate a classifier in the active learning workflow. The method of training a new classifier on the new sample library is the simplest and the most straightforward method only after the samples have been updated. However, considering that sample labels involve a lot of effort and the P sample set’s reliability is high, the team used a semi-supervised algorithm, Two-step PU Learning, to enhance the sample’s efficiency.
In a given dataset, PU Learning assumes that some black samples are already labeled to form set P (Positive), and that the remaining unlabeled data will form set U (Unlabeled). How does one build a model that can classify unlabeled samples into black and white categories? If one considers the sample tag in set U as missing, then one can also consider using the idea of EM (Expectation Maximization). EM can be understood as an improved version of the MLE (Maximum Likelihood Estimation) method in presence of hidden variables. Here, the team fills the missing values at step E, and iterate the algorithm at step M based on the last filed result. The process is repeated for many rounds until the final model, the original PU, is produced.
Two-step PU Learning is a development based on original PU Learning. If P is biased, then it cannot accurately represent the black samples as a whole, and multiple rounds of EM may have a negative effect. Two-step PU Learning introduces a spy mechanism to generate white samples more reliably. (Any mention of PU Learning in the remainder of this article refers to Two-step PU Learning, unless otherwise specified.)
Implementing Active PU Learning
Algorithm workflow
Algorithm: Active PU Learning
1. Generate a sample pool: Select the sample set needed for the task and apply positive tags to samples based on knowledge transferred from other areas
2. If the stop condition is not satisfied, then loop through steps 3 to 6 until the stop condition is satisfied
3. Conduct sampling: Based on a specific sampling method, select the sample to be labeled in the sampling process
4. Label: Manually label samples that are to be labeled
5. Update the sample: Update the sample library using a specific method
6. Update the model: Update the model using the Two-step PU Learning method
7. End the loop when the stop condition is satisfied
Compared to research carried out in the paper “Exploring semi-supervised and active learning for activity recognition,” by Stikic, Van Laerhoven, and Schiele, the team improved on the method by replacing sampling and model updating processes with batch sampling and Two-step PU Learning.
Sampling
Sampling and iteration are often streamed for Active Learning tasks, where a sample is first selected based on the current algorithm and then labeled, after which the algorithm is iterated, and another sample is selected based on the current iterated algorithm, and so on, making it an inefficient exercise. In instances where a hundred samples need to be marked, a hundred iterations are needed. This makes the time cost for large training datasets and complex models unacceptable.
As a time-friendlier alternative, the team uses a mini-batch method for batch sampling, sampling multiple records at a time, and updating the algorithm only after the sampling records are all labeled.
The sampling method is based on the Uncertainty & Diversity standard, which extracts the most uncertain yet diverse sample set. The specific procedure is as follows:
1. Use the current model to score new data Dnew.
2. Extract a number of unlabeled samples, of which the model has the most uncertainty, to constitute Duncertain; the measure of uncertainty is based on the scoring of the model.
3. Perform K-Means clustering on Duncertain and extract the most uncertain samples from each class to form the final sample set for labeling.
Labeling
Since our method relies solely on the information from set P, the expert must only label the samples that he/she has sufficient confidence in to judge as 1, in order to ensure the accuracy of the set.
Updating the sample
Samples labeled 0 by the expert are allocated to set U and treated as unlabeled. Samples labeled 1 are put into set P after multiple upsamplings to enhance their role in the next round of model updating.
Updating the model
Regular Active Learning is shown on the left in the figure below. The expert labels several samples, gradually expanding set L (Labeled), while the active learner continuously improves its performance by repeatedly studying the set, internally called an LU setting.
However, our scenario is actually closer to PU setting. The expert labels samples to expand set P (Positive), and the learner studies based on PU learning at each iteration.
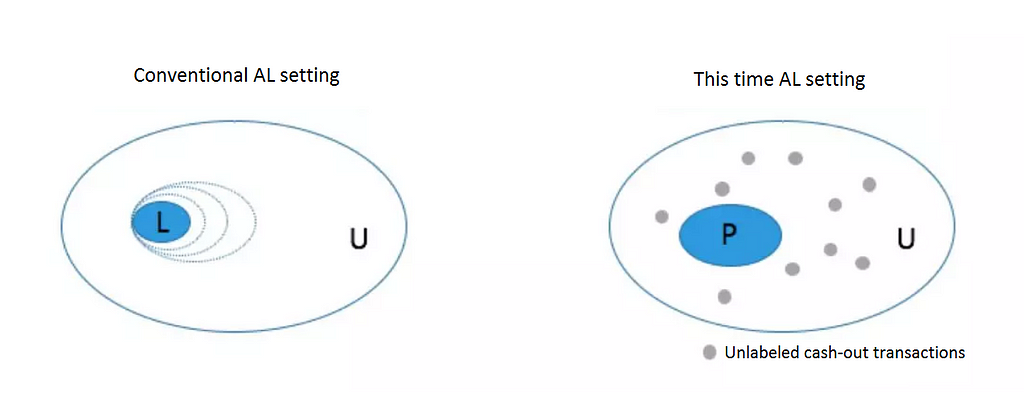 Regular active learning (left) vs. Alibaba’s implementation (right)
Regular active learning (left) vs. Alibaba’s implementation (right)
There are two reasons that weigh in favor of PU Learning. Firstly, it provides a chance for the new model to grow on the basis of existing knowledge. Currently, the team has a large number of basic module information to bring about black labels with high accuracy but low recall. Secondly, when the sample labeling volume is small, the information in set U (Uncertain) can be utilized in model training.
The team implemented the model update based on two-step PU, called so since it is divided into two steps. The first step involves mixing some spy samples from set P into set U and performing multiple rounds of EM iterations. The second step examines the score distribution of the spy samples, marking all samples in set U with a score less than 10% of the quintile score for spy samples as 0 to generate set N (Negative), and performing multiple rounds of EM iterations on this basis.
The EM iterative idea remains consistent in the two-step PU process. The sample score for set P is marked as 1. The sample score for set U inherits the model score from the preceding round, trains on the new fitting sample score, and gives a new model score to complete an iteration.
The team used Gradient Boosting Regression Tree (GBRT) as the base classifier for Active Learning, producing a GBRT model post the learning stage.
Experiments
The team designed three experiments to test the effectiveness of two-step PU, Active Learning, and Active PU Learning. To keep the exercise feasible, the three experiments adopted different settings and inspection methods. The sample size of all training sets across experiments was kept at an order of magnitude crossing a million, and all evaluation sets underwent special non-uniform sampling to improve calculation efficiency.
Effectiveness of Two-step PU Learning
The examination method was as follows:
1. Based on the same training datasets, three models were trained, including unsupervised model IF (Isolation Forest), supervised GBRT model, and a GBRT model generated iteratively by two-step PU Learning (referred as PU GBRT).
2. Credit card transactions from the same time period were used and scored by IF, GBRT, and PU GBRT models.
3. A number of samples were obtained by sampling at the 95th to 100th quintile from each group of scoring results.
4. The assessment results declared the accuracy rate for IF and GBRT at 60%, and at 70% for PU GBRT.
The results clearly show the PU model to be better.
Effectiveness of Active Learning
The examination process was divided into three sections:
1. Improvements in performance: The current unsupervised model was used for comparison to examine whether AL brought about any improvements in model performance.
2. Effectiveness of AL framework: The supervised GBRT model not using manually labeled data was used for comparison to determine whether the GBRT model trained by AL was an improvement over existing models.
3. Effectiveness of AL sampling: The supervised GBRT model trained by the same number of random sampling labels was used for comparison to ascertain whether the GBRT model trained by the AL sampling method was an improvement.
The method for examination 1 was as follows:
1. An unsupervised IF model was trained based on training dataset A.
2. Active Learning was applied to dataset A, and part of the data was additionally labeled to generate RF (Random Forest) (referred to as AL RF) through multiple iterations.
3. Credit card transactions from the same time period were used and scored by IF and AL RF.
4. Samples were obtained by sampling at over 99th, 95th to 99th, 90th to 95th, and 80th to 90th quintiles from each group of scoring results.
5. The assessment results held the accuracy rate for IF at 91%, and 94% for AL RF.
The results show that the model produced using AL is indeed better. The methods for examination 2 and 3 followed the same procedure with similarly positive results.
Effectiveness of the Active PU Learning System
The examination method was as follows:
1. An unsupervised IF model and supervised GBRT model were trained based on the same training dataset A.
2. Active Learning was applied to dataset A to generate a GBRT model (referred to as APU GBRT) through multiple iterations.
3. Credit card transactions from the same time period were used and scored by IF, GBRT, and APU GBRT.
4. Several samples were taken for manual labeling from the 85th to 90th, 90th to 95th, 95th to 99th, and 99th to 100th quintiles from each group of scoring results.
5. When compared horizontally under the same percentile, in terms of the labeling accuracy for different models, APU GBRT was deemed better than or equal to the other two models for each quintile.
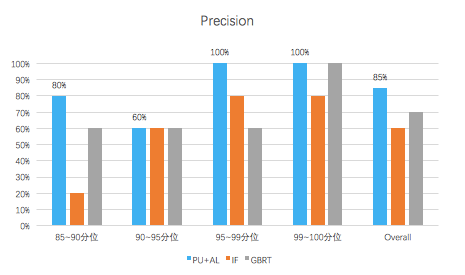 Comparing the accuracy of PU+AL to IF and GBRT
Comparing the accuracy of PU+AL to IF and GBRT
Summary and Outlook
Across industries and applications, it is common to find lacking tags or high tag acquisition costs for machine learning techniques. This prompts practitioners to implement various methods to build reliable models for such scenarios. The Active PU Learning method focuses on effectively introducing external information and making better use of existing knowledge of given tags to reduce costs.
Compared to traditional methods, Active PU Learning introduces two-step PU Learning to improve model updating methods in Active Learning, but even this comes at a price. The algorithm demands high-quality manual labeling, and the training process is also lengthier than for conventional GBRT.
When a model produced by Active PU Learning was applied to cash-in scenarios, it achieved a 3x improvement in identification rate when compared to using Isolation Forest at the same level of accuracy. As a methodology that has already been shown to be effective, there is a lot of potential for the Active PU Learning method, and the technology will likely continue to improve, and inspire other technologies, in the future.
(Original article by Lu Yicheng陆毅成)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”; Twitter: “AlibabaTech”.

Using AI for Mobile Wallet Fraud Prevention was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.