Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
What Are DAGs and How do they Work?
The purpose of this post is to clearly understand the idea behind the DAGs.
The best way to fully understand it to a deep level is to learning by reasoning that why are the things are the way they are. So, we are going to start with a really basic DAG and then try to build a robust and secure DAG network by logically introducing more complex things in a way that makes sense.
For this tutorial we are going to see how the tangle of IOTA works.
Directed graph
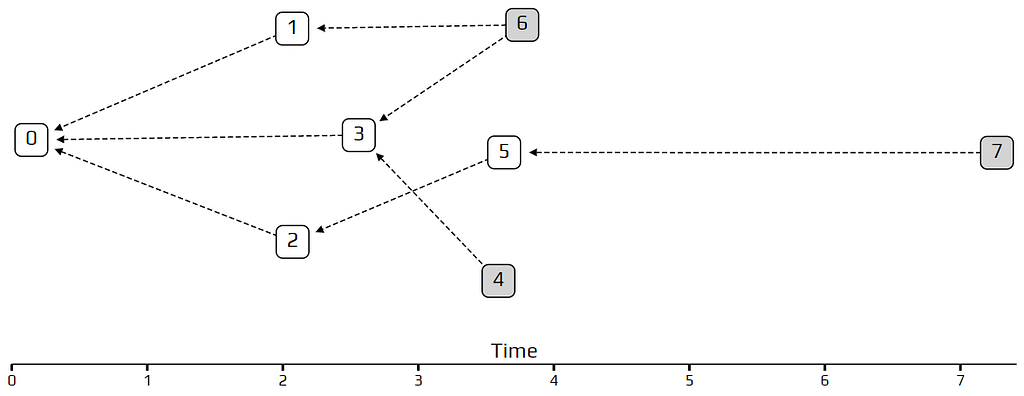
To understand the tangle, we need to learn about what computer scientists call a directed graph. A directed graph is a collection of vertices (squares), which are connected to each other by edges (arrows). This is an example of a directed graph:
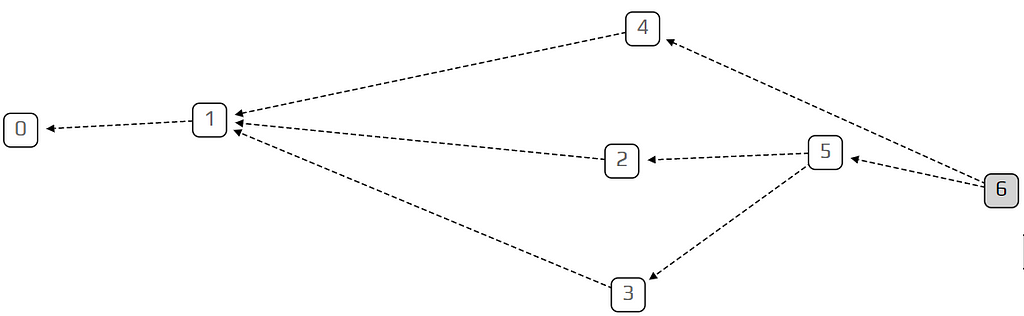
The Tangle, which is the data structure behind IOTA, is a particular kind of directed graph, which holds transactions. Each transaction is represented as a vertex in the graph. When a new transaction joins the tangle, it chooses two previous transactions to approve, adding two new edges to the graph. In the example above, transaction number 5 approves transactions number 2 and 3. Transactions are more or less what you would expect, information of the form “person A gave person B ten IOTAs”. At this stage we won’t worry too much about what we mean by approving a transaction, as we’ll get into that later.
We call unapproved transactions tips. In the example, transaction number 6 is a tip, because no one approved it yet. Each incoming transaction needs to choose two tips to approve (there is always at least one!). The strategy for choosing which two tips to approve is very important, and is the key to IOTA’s unique technology. However, to make our lives easier, we’ll start with the simplest strategy: choosing randomly between all available tips. Each incoming transaction looks at all the currently unapproved transactions, and simply chooses two at random.
To see what the tangle looks like when everyone uses this random selection strategy (technically called “uniform random tip selection”), you can play with this visual simulation of it. This simulation generates random tangles, with the very first transaction (called the genesis) on the left and the most recent transactions on the right. The tips are marked with a gray square. When you put your mouse over a transaction, all the transactions approved by it are highlighted in red, and all those which approve it turn blue.
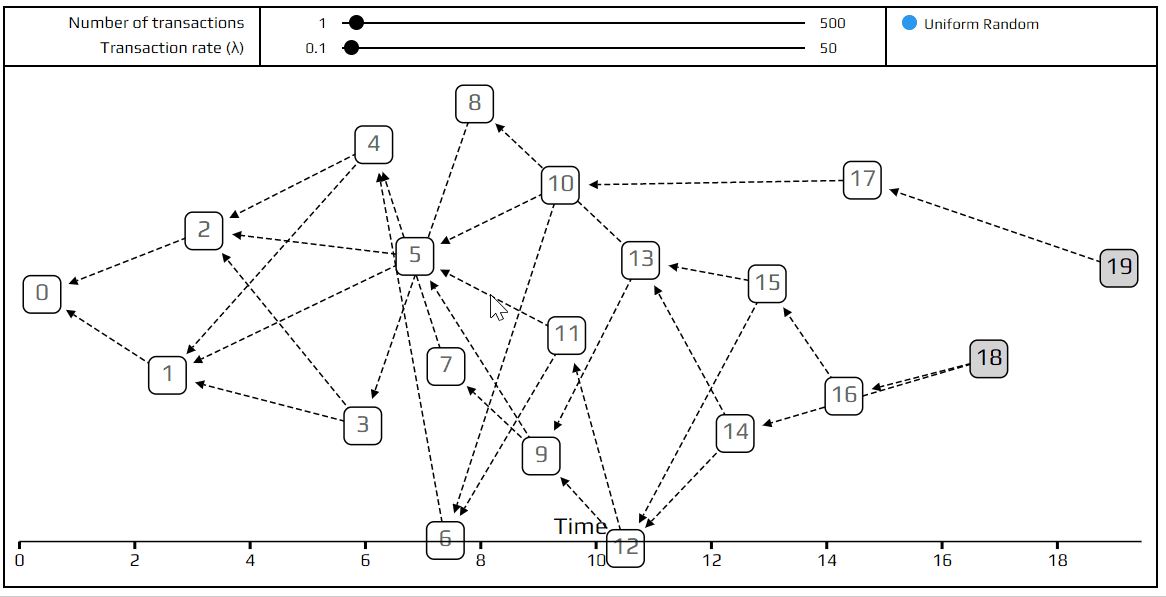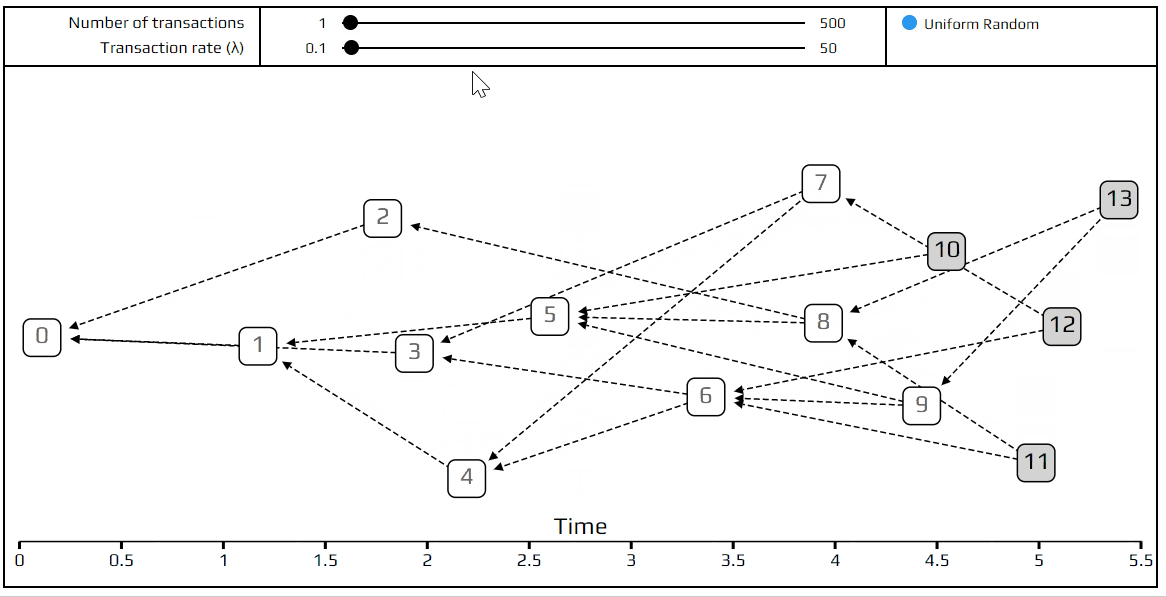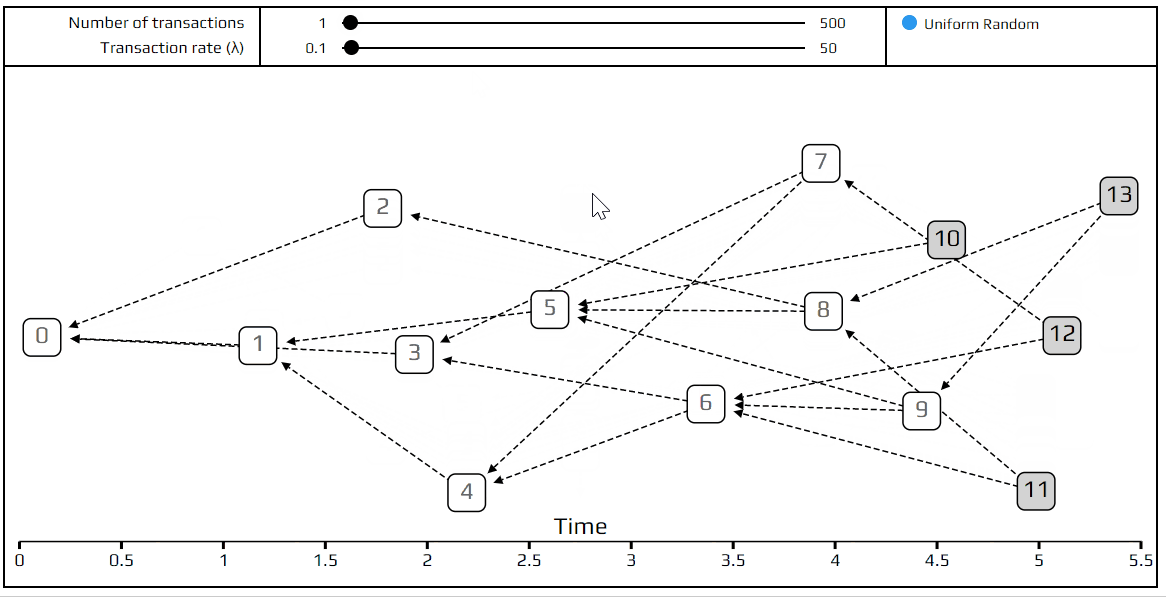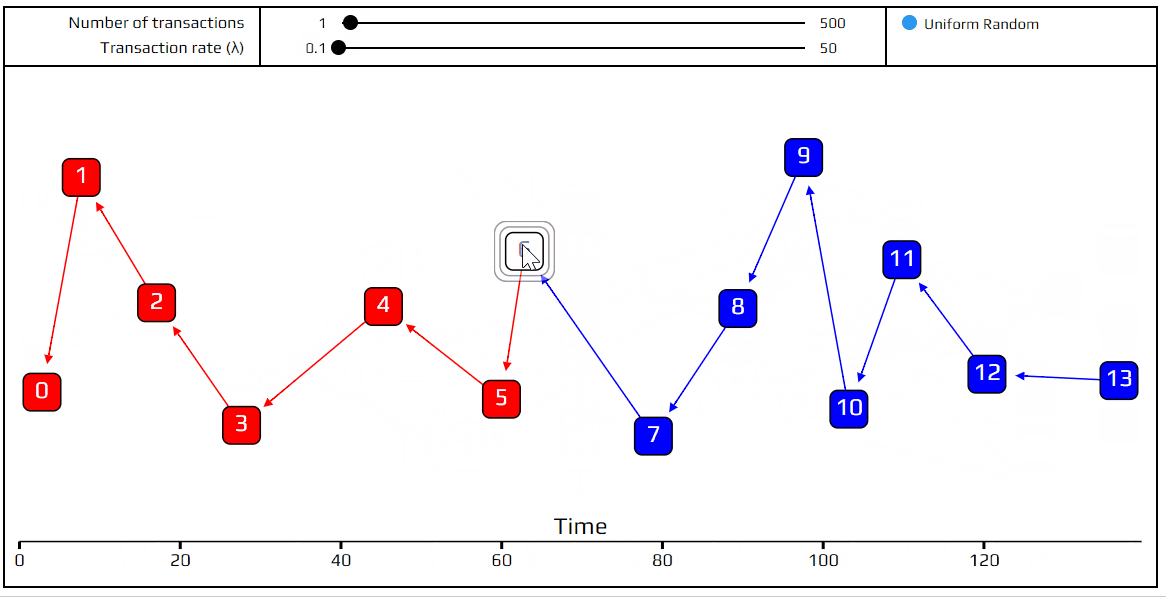
Transaction Rates and Network Latency
In previous simulation, you may have noticed that transactions are not evenly spread out across time, but some periods are “busier” than others. This randomness, which makes the model more realistic, is achieved by using a Poisson point process to model how transactions arrive. This model is very common for analyzing how many customers walk into a store in a given time period, or how many phone calls are made to a call center. We can see this behavior in example tangle below. Transactions 4, 5, and 6 arrived almost simultaneously, and after transaction 6 there was a long pause.
For our purposes, we only need to know one thing about this Poisson point process: on average, the rate of incoming transactions is constant, and is set by a number we call λ. As an example, if we set λ=2, and the number of transactions to be 100, the total simulation time will be about 50 time units. Try it out!
One more interesting thing to point out, before moving on: if we set λ to a very small amount (say 0.1), we get a “chain”. A chain is a tangle where transactions only approve one previous transaction, instead of two. This happens because transactions are coming in so slowly that at any given time there is only a single tip to approve. This is what actually happens in a blockchain. Thus DAGs are basically a generalized form of the blockchain. In the other extreme, with huge λ, all of the transactions arrive so fast that the only tip they see is the genesis. This is just a limitation of the simulation: with large λ and a fixed number of transactions, we are simulating a very short time period.
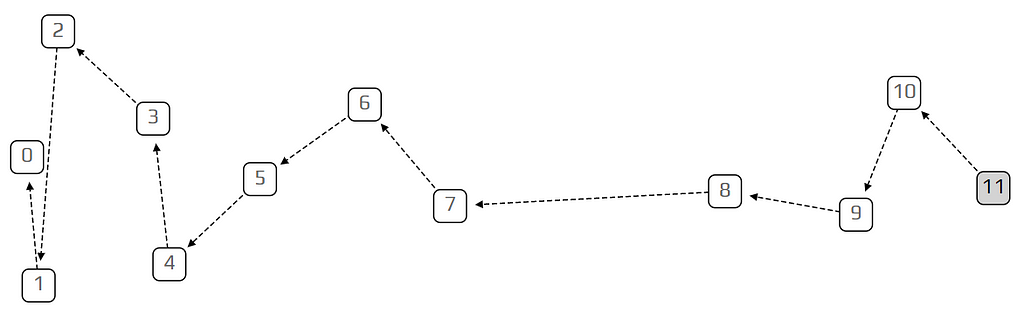
So what do we mean by the transaction not “seeing” a previous one? In the model, we make each transaction invisible for a certain period after it arrives. We mark this delay period with the letter h. This delay represents the time it takes for the transaction to be prepared and propagate through the network. In our simulation, we always set h=1. This means we can only approve transactions that are at least one time unit in the past. This delay is not just a minor detail that was put in for extra realism, but a fundamental property of the tangle, without which we will always get a very boring chain. It also brings the tangle closer to the real world, where it takes some time for people to tell each other about new transactions.
Random Walk
Finally, it’s time to talk about a more advanced tip selection algorithm: the unweighted random walk. Using this algorithm, we put a walker on the genesis transaction, and have it start “walking” towards the tips. On each step it jumps to one of the transactions which directly approves the one we are currently on. We choose which transaction to jump to with equal probability, which is where the term unweighted comes from. Here is a simulation that shows how this happens.
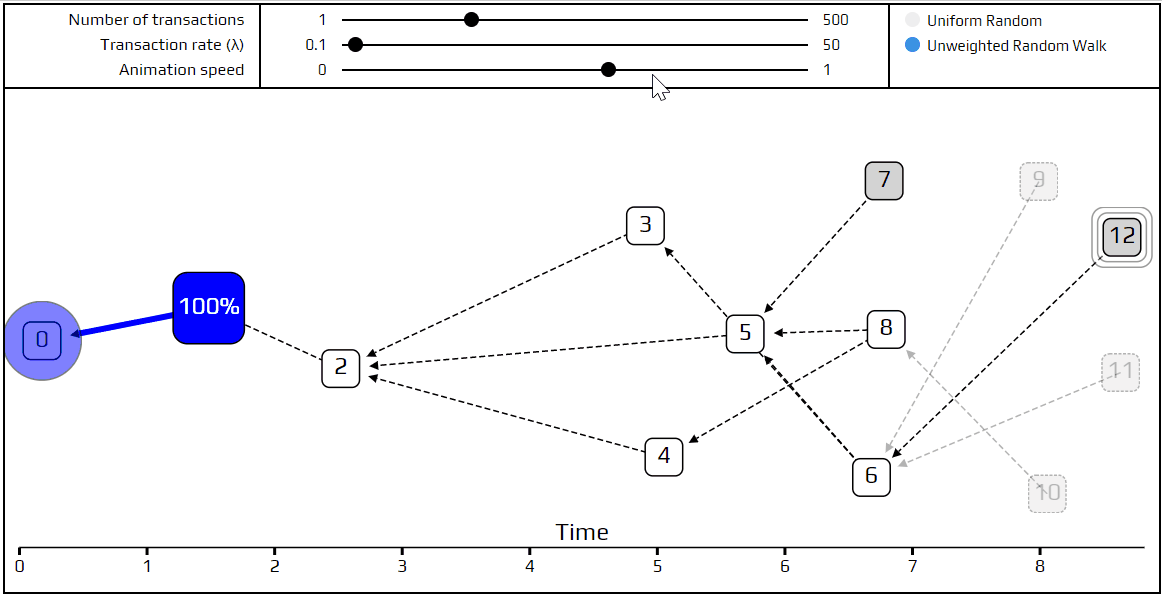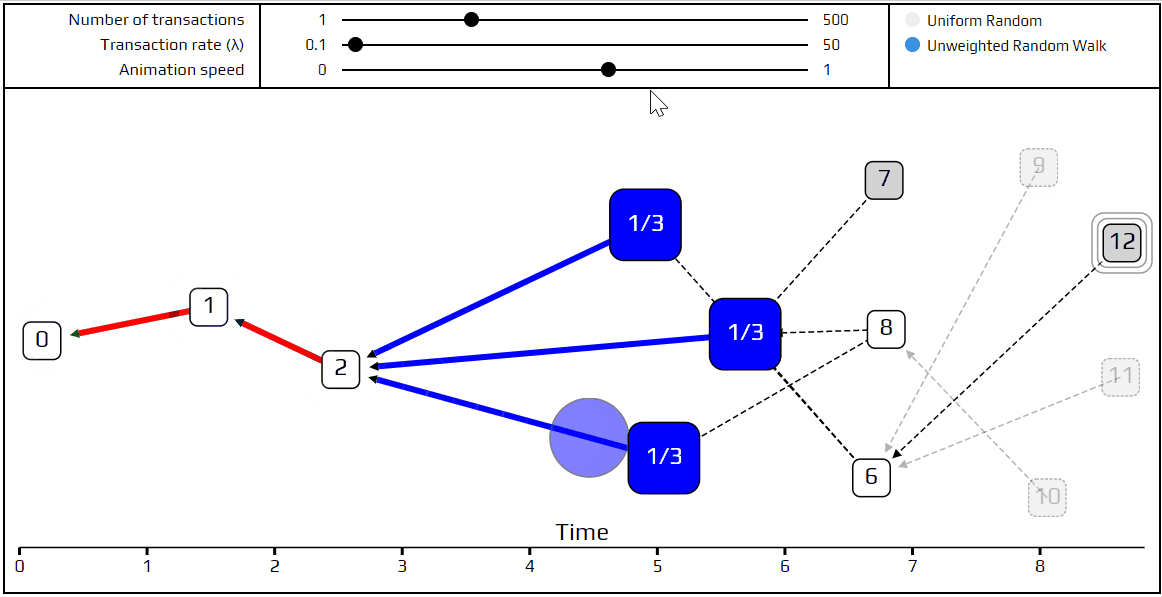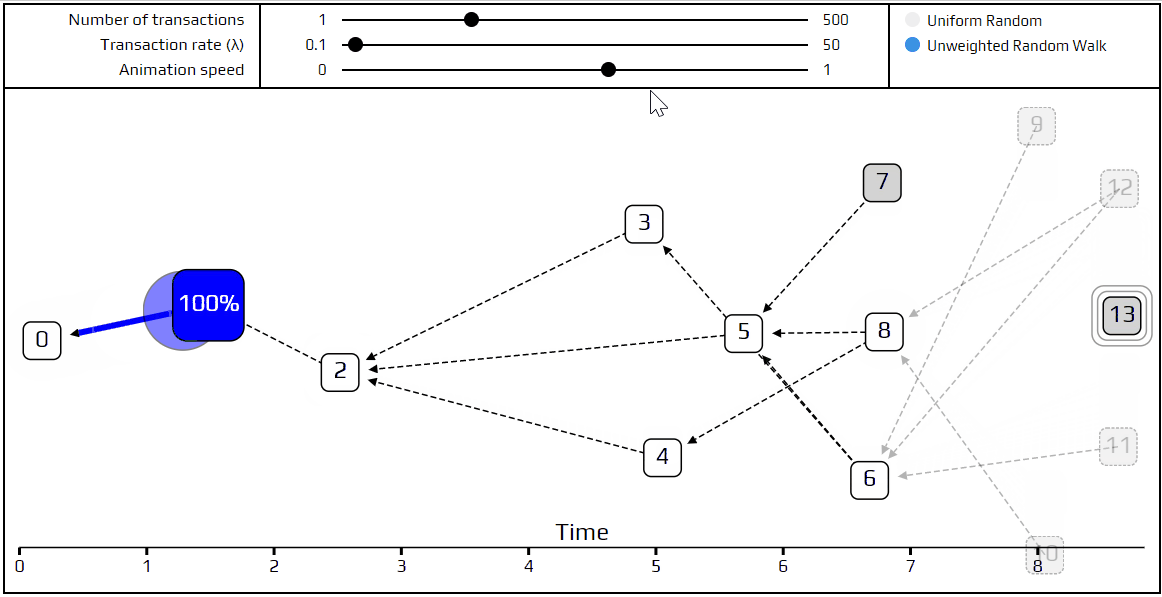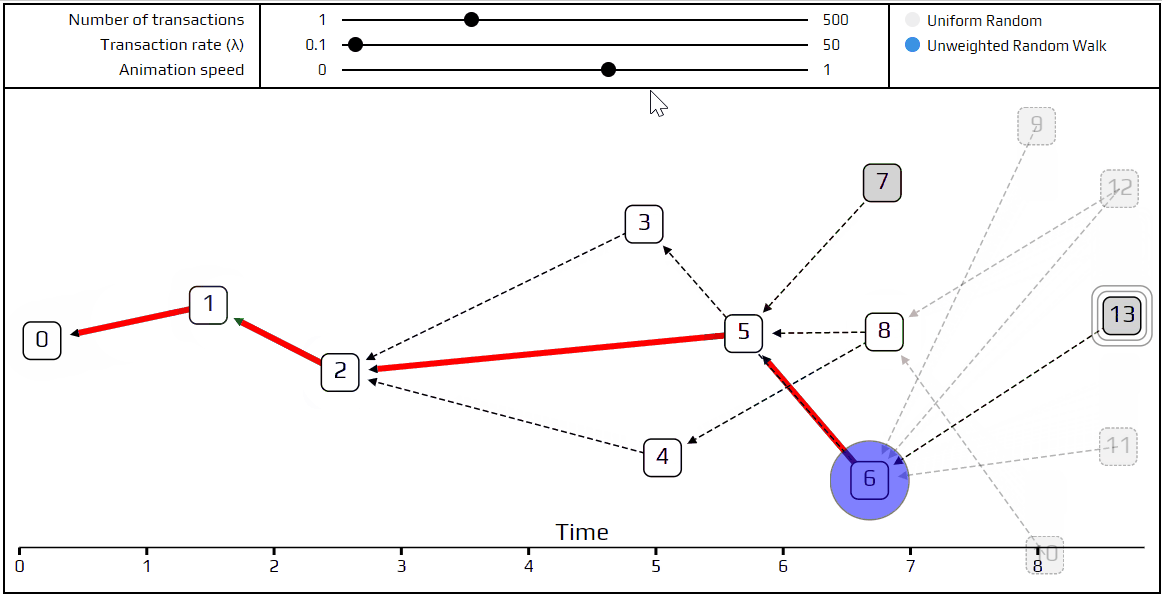
You can see the path the walker follows is marked in red, and at each junction the different possible paths are marked in blue. Very recent transactions, which are “invisible” to the current random walk, are shown as transparent.
Weighted Random Walk and Cumulative Weight
Let us begin with some motivation for studying it. One of the things we want our tip selection algorithm to do is avoid lazy tips. A lazy tip is one that approves old transactions rather than recent ones. It is lazy because it does not bother keeping up to date with the newest state of the tangle, and only broadcasts its own transactions based on old data. This does not help the network, since no new transactions are confirmed.
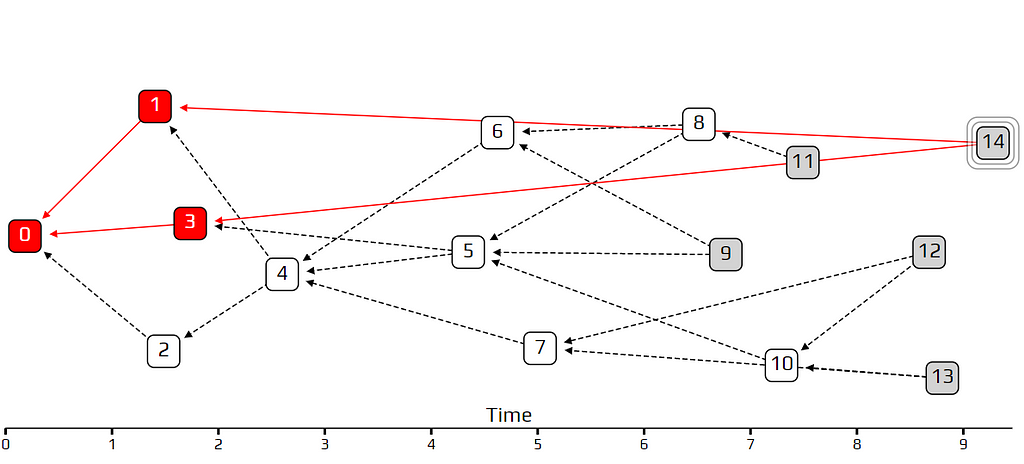
In the example above, transaction 14 is a lazy tip, which approves some very old transactions. If we use the uniform random tip selection algorithm, transaction 14 is just as likely to get approved as any other, so it is not being penalized at all. Using the unweighted walk, this bad behavior is even encouraged, at least in the previous simulation.
How can we deal with this problem? One thing we cannot do is force participants to only approve recent transactions, since that would clash with the idea of decentralization. Transactions can approve whomever they please. We also don’t have an reliable way of telling exactly when each transaction came in, so we cannot enforce such a rule. Our solution is to construct our system with built-in incentives against such behavior, so that lazy tips will be unlikely to get approved by anyone.
Our strategy will be to bias our random walk, so we are less likely to choose lazy tips. We will use the term cumulative weight to denote how important a transaction is. We are more likely to walk towards a heavy transaction than a light one. The definition of cumulative weight is very simple: we count how many approvers a transaction has, and add one. We count both direct and indirect approvers. In the example below, transaction 3 has a cumulative weight of five, because it has four transactions which approve it (5 directly; 7, 8, and 10 indirectly).
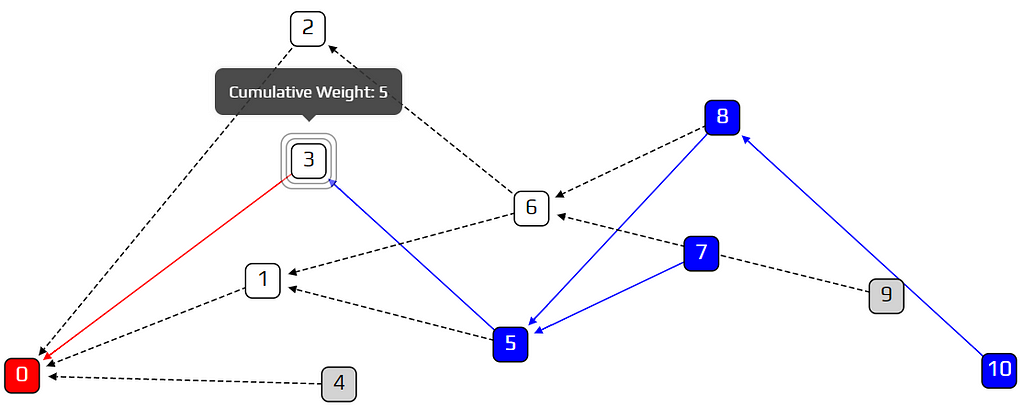
Why does this work? Let’s have a look at another lazy tip situation. In the example below, transaction 16 is a lazy tip. In order for 16 to get approved, the random walker must reach transaction 7, and then choose transaction 16 over transaction 9. But this is unlikely to happen, because transaction 16 has a cumulative weight of 1, and transaction 9 has a cumulative weight of 7! This is an effective way of discouraging lazy behavior.
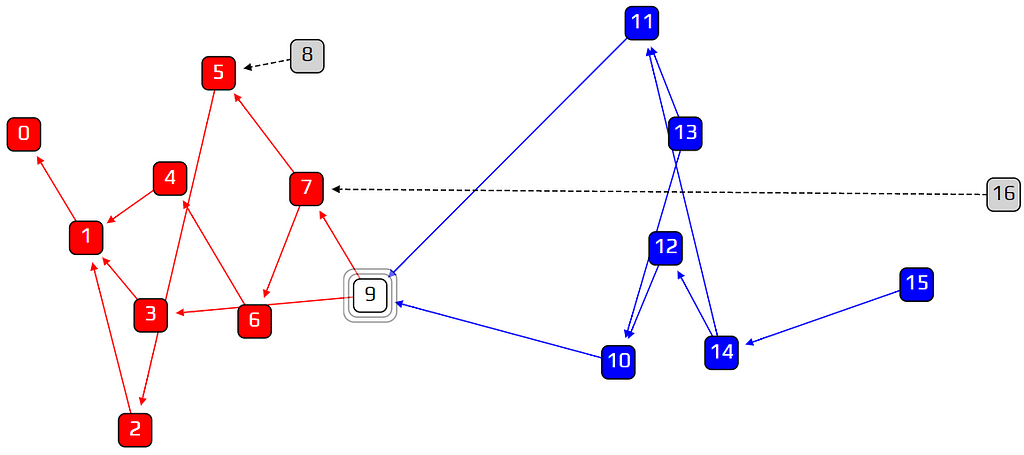
At this point we might ask: do we need randomness at all? We can invent the super-weighted random walk, where at each junction we choose the heaviest transaction, with no probabilities involved. We will then get something like this:
The gray squares are tips, with zero approvers. While it is normal to have some tips on the right end of the diagram, it is a problem to see so many of them spread out across the timeline. These tips are transactions that are left behind, and will never be approved. This is the down-side to biasing our walk too much: if we insist on choosing only the heaviest transaction at any given point, a large percentage of the tips will never get approved. We are left with only a central corridor of approved transactions, and forgotten tips on the sidelines.
We need a method to define how likely we are to walk towards any particular approver at a given junction. The exact formula we choose is not important, as long as we give some bias to heavier transactions, and have a parameter to control how strong this bias is. This introduces our new parameter α, which sets how important a transaction’s cumulative weight is. Its exact definition can be found in the IOTA’s white paper, and if there is demand I might write a future post giving some more details on it.
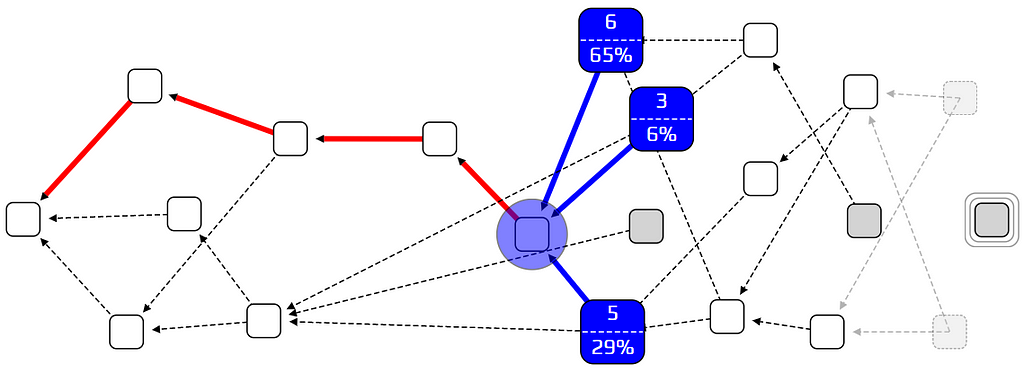 The weighted random walk: each blue transaction shows its cumulative weight, and its probability of being chosen as the next step in the walk.
The weighted random walk: each blue transaction shows its cumulative weight, and its probability of being chosen as the next step in the walk.
If we set α to zero, we go back to the unweighted walk. If we set α to be very high, we get the super-weighted walk. In between, we can find a good balance between punishing lazy behavior and not leaving too many tips behind. Determining an ideal value for α is an important research topic in IOTA.
This method of setting a rule for deciding the probability of each step in a random walk is called a Markov Chain Monte Carlo technique, or MCMC. In a Markov chain each step does not depend on the previous one, but follows from a rule that is decided in advance.

As always, we have a simulation to demonstrate these new ideas. I recommend playing around with the values of α and λ, and seeing what kind of interesting tangles you can cook up.
Approvers, Balances and Double-spends
So far we talked about DAGs, random walks, and various tip selection mechanisms; this time we will talk about money. The time has come to explain what we mean when we say that transaction A approves transaction B.
As mentioned above, each transaction contains information of the form “Alice gave bob 10 IOTAs”. It is the approver’s job to make sure that Alice really had those 10 IOTAs to give in the first place.
You might wonder at this point: where did these IOTAs come from? The answer is that they were all created in the very first transaction in the tangle, called the genesis transaction. No additional IOTAs will ever be created. From the genesis the IOTAs were transferred to the accounts of the original investors in the project, in proportion to the amount they put in. Afterwards, they sold some of their IOTA to others, and a trading network was eventually established.
Coming back to Alice and Bob, let’s look at a simple example. The box represents a transaction. For convenience, we also write down the balances in Alice and Bob’s accounts before and after the transaction took place. We see that in the beginning Alice had 10i, which she gave to Bob, after which Bob has 10i and Alice has nothing.

Eventually someone, say Charlie, wants to make his own payment. He runs the tip selection algorithm, and it turns out he needs to approve Alice’s transaction. To do that, he must verify that Alice really had the 10i she spent. Charlie had better take this task seriously: if he approves a bad transaction, his own transaction will never be approved!
To be absolutely sure, Charlie has to list all the transactions approved directly and indirectly by Alice’s transaction, all the way back to the genesis. He ends up with a long list, which may look like this:
- Genesis creates 15i
- Genesis gives Bob 2i
- Genesis gives Alice 8i
- Genesis gives Charlie 5i
- Charlie gives Donna 3i
- Bob gives Alice 2i
This is just one option of course; any list that ends up with 10i in Alice’s account and 0 in Bob’s is acceptable. Charlie also has to keep track of all the other accounts in the system, to make sure they do not go below zero: if any of the balances in the “before” or “after” sections are negative, his transaction is invalid.
Let’s have a look at at a case where Alice tries to give more IOTAs than she has:

Alice paid Bob 100i even though she only had 10. Alice’s transaction, and any future transaction that approves it, are considered invalid by the network. Negative balances are not allowed.
The situation gets more interesting when we approve two transactions rather than one:
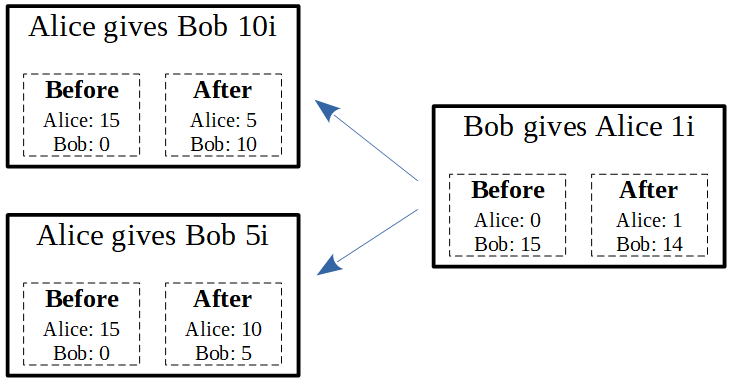
Bob was correct in approving Alice’s transactions, because she had just enough money in her account to pay both without going below zero.
What would happen if the total is more than she has? This is shown below. In this case, Bob cannot approve both of Alice’s transactions, because they result in a negative balance for Alice. If Bob does this, he is breaking the rules of the IOTA protocol, and no one will approve his new transaction.
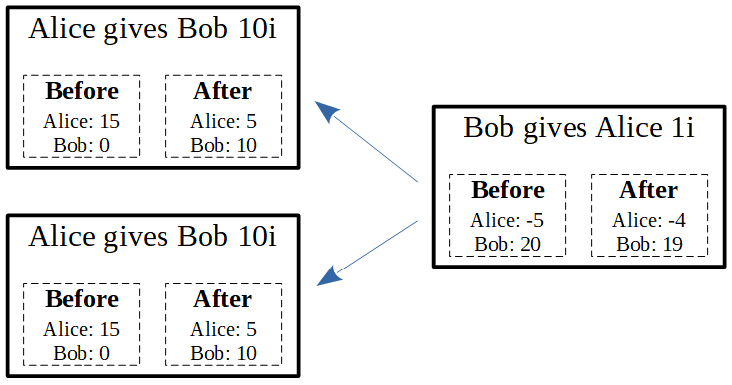
This last situation is called a double spend, because Alice spent her money twice. Notice that she did not break the protocol, because she had enough money for each individual transaction. Maybe she did not even mean to double-spend, but sent her transaction twice by mistake. She did however create two branches in the tangle that cannot be reconciled. This creates a problem for honest users of IOTA: which branch should they approve?
The solution to this problem is once again the weighted walk we learned about last week. Eventually one of the branches will grow heavier than the other, and the lighter one will be abandoned. This also implies that a transaction cannot be considered to be confirmed immediately after it is issued, even if it has some approvers, since it might be part of a branch that will be abandoned eventually. In order to be sure your transaction is confirmed, you have to wait for its confirmation confidence to be high enough.
Consensus, Confirmation confidence and the Coordinator
We just mentioned the double-spend problem, which arises when Alice tries to spend her money more than once. Now, we will show how this problem is resolved in the Tangle, and how we decide which history is the valid one.
To illustrate the problem, we will examine the following double spend scenario:
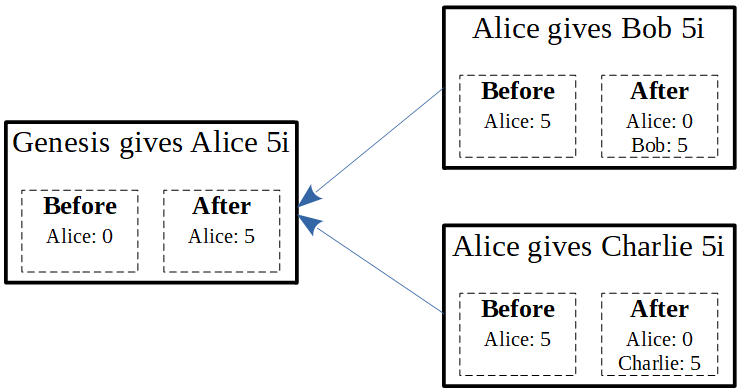
As you can see, Alice has 5i, which she gives to both Charlie and Bob. This is clearly a problem: we cannot treat both these transactions as valid. Using Tangle terminology, we cannot have a future transaction approving both of them, since it will end up with a negative balance in Alice’s account.
We have learned that using the weighted random walk algorithm, eventually one of the branches will become much larger. Thus a consensus is formed around which transaction is valid. From the perspective of Bob or Charlie, however, there is a problem: how do they know if they really got the money from Alice?
Imagine Bob and Charlie are dinosaur dealers, and Alice purchased a pet T-Rex from each of them. If they both send her the T-Rex immediately after seeing her transaction in the Tangle, eventually one of them will discover he has not been paid. How can they know when it is safe to ship the lizard?
This is a serious problem, and in fact, Bitcoin was the first technology to successfully deal with it, back in 2009. To show how the Tangle solves it, we introduce a concept called confirmation confidence. This confidence is a measure of a transaction’s level of acceptance by the rest of the tangle.
The confirmation confidence of a transaction is computed as follows:
- Run the tip selection algorithm 100 times.
- Count how many of those 100 tips approve our transaction, and call it A.
- The confirmation confidence of our transaction is “A percent”.
In other words, the confidence of a transaction is the percentage of tips which approve it. Not all tips are considered equally; more likely tips are given more importance. To illustrate this point, let’s add confirmation confidence to the simulation. Transactions with a confidence of over 95% are shown with a thick border around them.
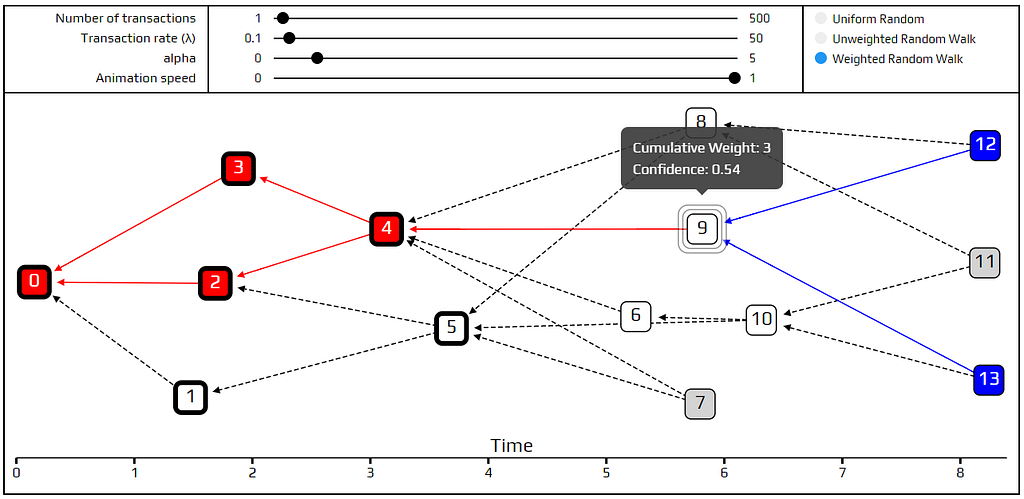
In the tangle above, transaction 9 is approved by two out of the four tips. If we were using uniform random tip selection, it would have a confidence of exactly 50%. However, the tips that approve it are apparently more likely than the tips that do not, which raises the confidence a bit.
Now it is clear how Bob and Charlie can tell when it is safe to send their T-Rex to Alice. Once Alice’s transaction reaches some very high confidence threshold, say 95%, it is very unlikely that it will be pushed out of the consensus. We should be careful and say very unlikely, rather than impossible; if Alice wants to cheat, and has enough computational power, she can try to double-spend.
To do that, she will issue a transaction paying Charlie, instead of Bob. She will have to approve two old transactions with it, which do not reference her payment to Charlie. She will then start issuing as many transactions as she can, trying to raise the cumulative weight of her new branch. If she has enough computational power, she can cause the entire IOTA network to believe her and follow her new branch, thus re-writing history and successfully double-spending. If we look at the confidence level of her transaction to Bob, we will see it declining from 95% to eventually zero.
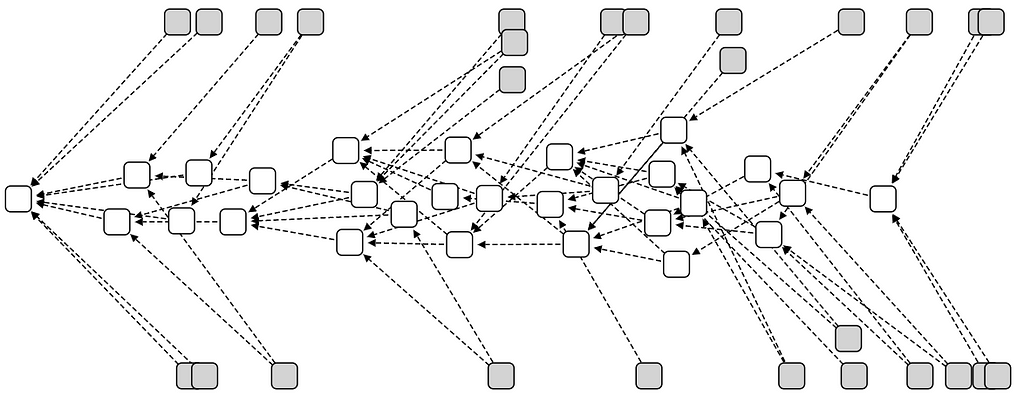
This attack is illustrated in the tangle below, with time going downwards:
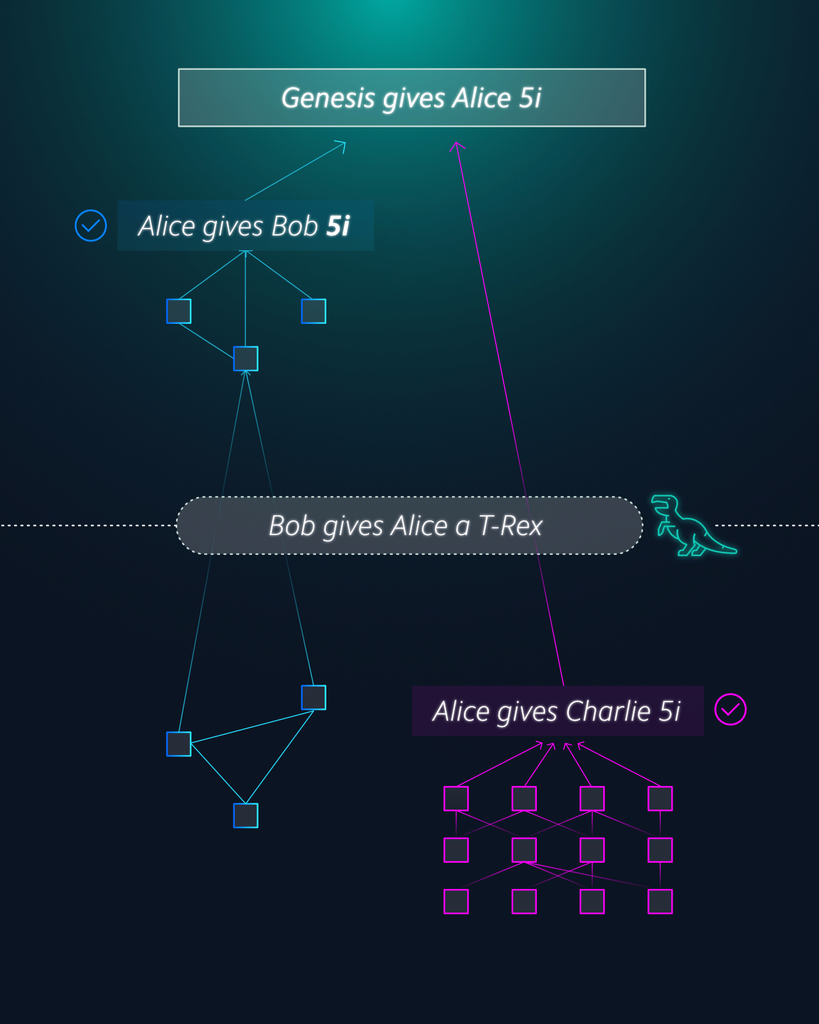 A double-spend attack
A double-spend attack
This scenario is only a risk if Alice can send more transactions than everyone else combined, or close to it. While not a major risk in a mature and active network, it is a real problem for today’s IOTA. There are not enough transactions going through the system for it to be safe from a concentrated double-spend attack.
Since IOTA was built for scaling we employ a voluntary and temporary different consensus mechanism for security reasons: the coordinator. Every two minutes, a milestone transaction is issued by the IOTA Foundation, and all transactions approved by it are considered to have a confirmation confidence of 100%, immediately. Using the coordinator, Alice’s second transaction will never have been approved in the first place. This acts as a protective mechanism while the IOTA network keeps growing toward the necessary activity from adoption needed to keep the network secure in a 100% decentralized manner, where the full Tangle distributed consensus algorithm kicks in. At that point the IOTA Foundation will shut down the Coordinator and let the Tangle evolve entirely on its own. This will happen in iterative phases. When the network is mature enough to get rid of the Coordinator the network will also instantly become orders of magnitude more efficient.
How is it Different from Blockchains?
The way DAGs are different from Blockchains is that it changes the inherent structure of the way we store the transactions. This change, however small it may seem, changes the way we see the things happening in the network. It makes the overall system far more robust than a blockchain. But there is always a catch. This increase in scalablity comes with poorer security, more probability to Centralization and inability to inherently support smart contracts. We will discuss more about Blockchains vs DAGs in the next post. Stay Tuned!
Thanks for reading;)

About the Author
Vaibhav Saini is a Co-Founder of TowardsBlockchain, an MIT Cambridge Innovation Center incubated startup.
He works as Senior blockchain developer and has worked on several blockchain platforms including Ethereum, Quorum, EOS, Nano, Hashgraph, IOTA etc.
He is currently a sophomore at IIT Delhi.
Learned something? Press and hold the 👏 to say “thanks!” and help others find this article.
Hold down the clap button if you liked the content! It helps me gain exposure .
Want to learn more? Checkout my previous articles.
- ConsensusPedia: An Encyclopedia of 30 Consensus Algorithms
- Getting Deep Into Ethereum: How Data Is Stored In Ethereum?
- ContractPedia: An Encyclopedia of 40 Smart Contract Platforms
- Difference between SideChains and State Channels
Clap 50 times and follow me on Twitter: @vasa_develop

A Beginner’s Ultimate Guide To DAGs was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.