Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Before there were Data Lakes and big data tools, there were Datamarts and the Data Vault.
This is a beginners overview of some of the terminology used by Business Intelligence teams in their data architecture.
Datamarts
This is the data that’s aggregated, modeled and structured so that you can build a report over the top of it. Your friendly BI Consultant has gathered the requirements from the business, agreed on the business rules and logic, then modeled the data to be user-friendly.
The Datamarts tables are organised in one of two forms. A ‘Star’ schema and a ‘Snowflake’ schema and are made of two types of tables.
Dimension Tables for Attributes
The Dimension table contains attributes or thing that describe. In the case of a User, this could be their first name, last name, age, etc. In the case of a Product, this could be it’s weight, colour or date of manufacture. These attributes should not be repeated in other tables around the database.
Fact Tables for Measures
The Fact table is used for counting how many times something has happened. How many orders, payruns etc. They are used to capture an action that can then be joined back to a Dimension table.
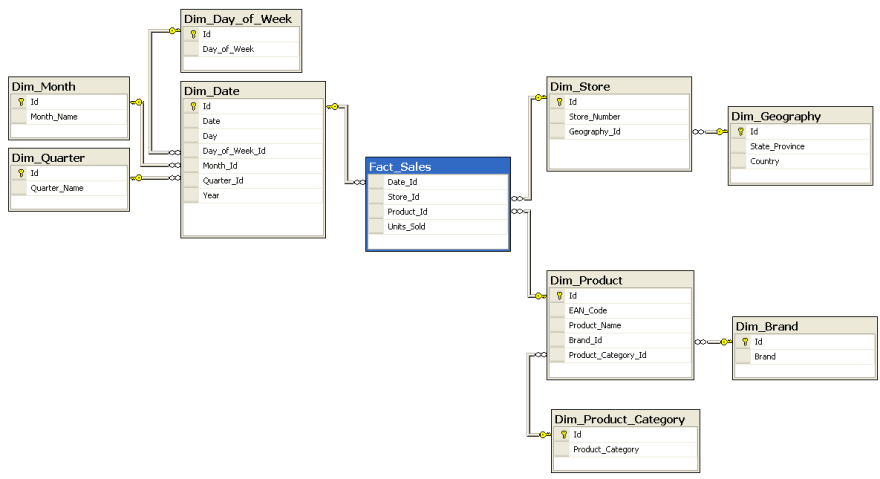 Example of a Snowflake schema by SqlPac at English Wikipedia, CC BY-SA 3.0
Example of a Snowflake schema by SqlPac at English Wikipedia, CC BY-SA 3.0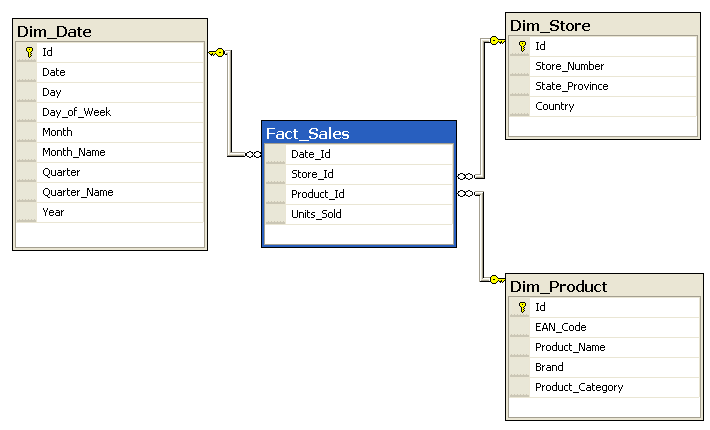 Example of a Star schema by SqlPac at English Wikipedia, CC BY-SA 3.0
Example of a Star schema by SqlPac at English Wikipedia, CC BY-SA 3.0
Data Vault
The Data Vault is used to store source data at a more granular level. Generally, the data is not changed in any way, other than to add load date keys to track changes. These are the tables that build the Datamart tables.
Tables come in three types:
Sats (Satellites)
These are the complete source tables that contain descriptive information and time attributes so we can track changes and do point-in-time analysis.
Hubs
These contain the business keys and any metadata. Nothing descriptive is written to a Hub.
Links
Links connect one or more Hubs together.
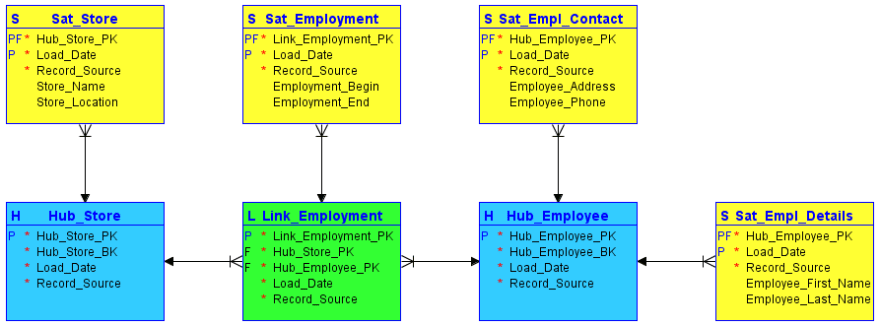 Example of a simple data vault model by Carbidfischer at English Wikipedia, CC BY-SA, CC BY-SA 4.0
Example of a simple data vault model by Carbidfischer at English Wikipedia, CC BY-SA, CC BY-SA 4.0
Data Lake
The Data Lake is designed to contain raw data in its most granular form at low cost. Data can be:
- Structured — tables from databases.
- Semi-structured — csvs and log files.
- Or not structured at all — images, emails and documents.
Data stored here is retrieved and read when required and organised based on need, making it popular with data scientists who would rather keep the quirks and ‘noise’ in, rather than having it cleaned and aggregated.
Data Swamp
Beware … the Data Swamp.
Even though the Data Lake concept gives more freedom to load data of all shapes and sizes, without a catalogue of entities, things get messy.
This isn’t just a matter of not knowing what’s in your Data Lake. If there are no controls over what kind of personal data is landed there could also be privacy issues.
Originally published at dev.to.
Datamarts, Data Vault, Data Lake… Data Swamp? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.