Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
SQL Best Practices — Designing An ETL Video
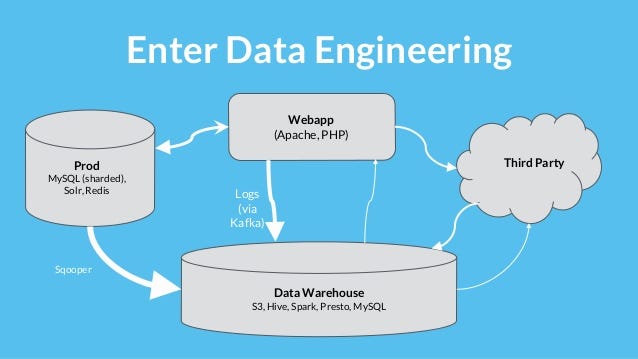
Data engineering has many facets. One of the most common projects a data engineer takes on is developing an ETL pipeline from an operational DB to a data warehouse. Our team wanted to cover the overarching design of an ETL.
What are the typical principal components, stages, considerations, etc?
We started this by first writing Creating An ETL Part 1(more to come) and we and now have worked on a video that is below that walks through the process. We wanted to discuss why each stage is important and what occurs when data goes from raw to stage, why do we need a raw database and so on.
Data engineering is a complex discipline that partners automation, programming, system design, databases, and analytics in order to ensure that analysts, data scientists and end-users have access to clean data.
This all starts with the basic ETL design.
We are practicing up for a webinar that we will be hosting on ETL development with Python and SQL. The webinar itself will be much more technical and dive much deeper into each component described in the video. However, we wanted to see how using the whiteboard was like in case we need it.
If you would like to sign up for the free webinar we will be hosting it on February 23rd at 10 AM PT. Feel free to sign up below! If you have other questions please do contact us.
SQL Best Practices — Designing An ETL Video was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.