Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Gentrification is a loaded term that is seen in both a positive and negative light. On the one hand, gentrification raises the value of property enriching existing house owners, on the other hand it pushes the price of rentals up, driving out non-house owners who may have lived in that neighbourhood their entire lives. One place that has experienced massive change over the last 2 or so decades is Brooklyn. Gentrification has driven up property and rentals so much so that even the Marvel Cinematic Universe's Captain America, despite being an Avenger, indicated that he could not afford to stay there.
 Captain America seemingly looking up in awe at Brooklyn property prices Source: DeadBeatsPanel
Captain America seemingly looking up in awe at Brooklyn property prices Source: DeadBeatsPanel
For this analysis I decided to download a Kaggle dataset on Brooklyn Home Sales between 2003 and 2017, with the objective of observing home sale prices between 2003 and 2017, visualising the most expensive neighbourhoods in Brooklyn and using and comparing multiple machine learning models to predict the price of houses based on the variables in the dataset.
Exploring the Data
I found it appropriate to start my analysis by visualising the distribution of house sale prices by year to possibly spot potential outliers and get a better understanding of interesting trends in my dataset.
housing_data = pd.read_csv('/content/gdrive/My Drive/Self Learning/Kaggle Projects/Brooklyn Home Sales 2003-2017/brooklyn_sales_map.csv')#scatterplot visualisationplt.scatter(x=housing_data['year_of_sale'],y=housing_data['sale_price'])ax =plt.gca()ax.get_yaxis().get_major_formatter().set_scientific(False)plt.draw()
Since the sale prices involve large numbers, the y-axis tick marks are by default returned in scientific format with exponential notation. I would general prefer visualising the distribution with the yaxis tick marks as standard numbers. In the matplotlib library tick labels are controlled by a Formatter object that allows for customisation of tick marks. In order to achieve my desired result I called the ScalarFormatter and turned off the default scientific notation format.
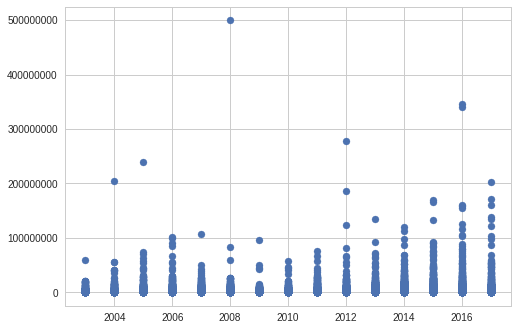 House sale prices by year
House sale prices by year
According to the visualisation, the highest recorded sale between 2003 and 2017 was for around $500million in 2008. Given how much of an outlier this sale is, I would assume that this is either factory, retail or commercial space.
housing_data.sort_values('sale_price').tail(1)Out of curiosity I decided to look into this outlier sale a bit more to understand the type of property that was acquired.
 Most expensive property sold
Most expensive property sold
This presumably refers to 28 commercial properties sold in one building in Downtown Brooklyn explaining the ±$500million sale price.
Summary Statistics
housing_data['sale_price'].describe().apply(lambda x: format(x, 'f'))
To better explore the mean, maximum and minimum prices, I returned the summary statistics on the sale price column and applied a lambda function to show the statistics in simple numbers as opposed to scientific notation.
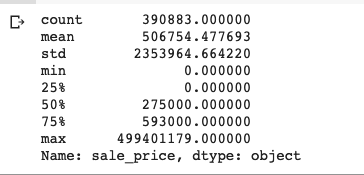 Summary Statistics
Summary Statistics
Interestingly, I found that that the 25th percentile house sales were priced at $0. I assumed that these where either incorrectly recorded or cases where the property was transferred from one party to another possibly through inheritance or something similar. Following this assumption, I concluded that these entries where not relevant for my analysis and proceeded to filter them from my dataset.
housing_data = housing_data[housing_data.sale_price > 0]
More visualisations
I find stacked bar-charts to be very helpful in exploring my data further. In this context a stacked bar chart showing the distribution of sales prices between 2003 and 2017 grouped by price ranges would give me an understanding of where the purchases are coming from (e.g higher-end luxury homes and commercial property sales or mid-range sales).
bins=[-100000000,20000,40000,60000,80000,100000,1000000,10000000,500000000]choices =['$0-$200k','$200k-$400k','$400k-$600k','$600k-$800k','$800k-$1mlln','$1mlln-$10mlln','$10mlln-$100mlln','$100mlln-$500mlln']housing_data['price_range']=pd.cut(housing_data['sale_price'],bins=bins,labels=choices)
I started off by grouping sale prices in pricing ranges for better visualisation. Instead of using if then statements the cut function allows you to put numbers into bins and convert those those to categorical values which in this instance would be price ranges.
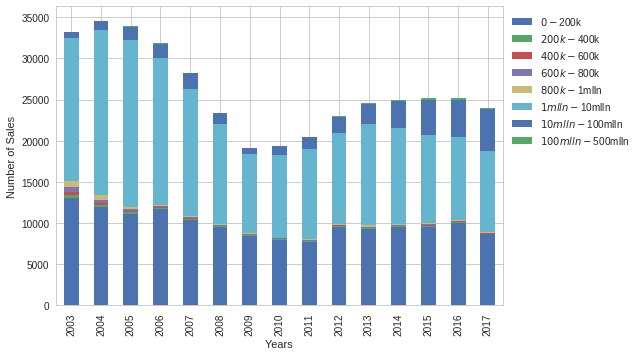 House prices by year grouped by price ranges
House prices by year grouped by price ranges
After grouping the data by year of sale and price ranges, the stacked bar chart seemed to indicate that a bulk of sales where in the $1million to $10million mark. To better visualise number of sales by price range over the years, I opted to convert absolute number of sales to percentages with the goal of showing what percentage sales in each price range constituted in a given year.
def conv(year): return housing_data[housing_data['year_of_sale']==year].groupby('price_range').size()perc_total = [x/sum(x)*100 for x in [conv(2003),conv(2004),conv(2005),conv(2006),conv(2007),conv(2008),conv(2009),conv(2010),conv(2011),conv(2012),conv(2013),conv(2014),conv(2015),conv(2016),conv(2017)]]year_names = list(range(2003,2018))housing_df = pd.DataFrame(perc_total, index= year_names)With the above code, I created a function and utilised list comprehension to convert sales data of each year into percentages. I then created a list of column labels ranging from 2003 to 2017, matched these to the percentages in the first list and created a dataframe from those two lists. Doing this created a dataframe showing percentage of sales by pricing range for each year in the original dataset.
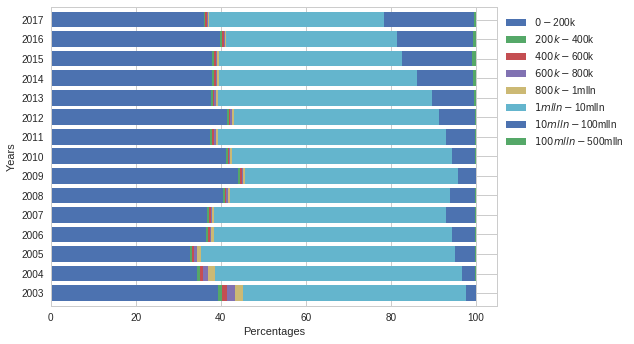 Proportion of property sales grouped by price range between 2003 and 2017
Proportion of property sales grouped by price range between 2003 and 2017
From this chart we see a significant increase in sales in the $10 million to $100 million mark. This wide price range captures sales in both the highly luxurious, commercial and retail property range indicating a strong migration of wealth into Brooklyn from both an individual and commercial perspective. Despite the high proportion of $1million -$10 million sales and the increase in sales the $10million - $100 million, sales under the $200 000 mark have remained fairly consistent. Although Brooklyn is rapidly getting gentrified there are still some houses going for very affordable prices.
Since there are many neighbourhoods in Brooklyn, I wanted to understand where the most and least expensive property is, at-least according to housing sales data. To visualise this data I used the groupby function to show housing sales grouped by price range distributed over the neighbourhoods presented in the dataset.
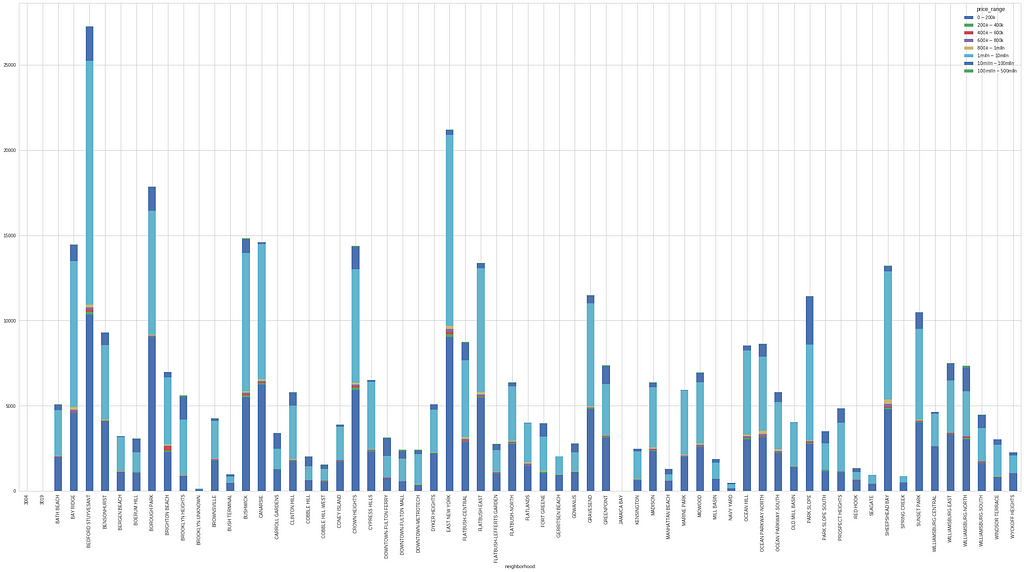
Bedford Stuyvesant leads the pack in terms of total house sales. Places such a Canarsie, East New York, Flatbush East, Sheepshead Bat, Sunset Park, Bushwick and Kensington to name a few, appear to have a very high concentration of high priced sales (sales exceeding $1million). There are still high volumes of sales in the <$200k mark, in a lot of neighbourhoods. It seems as though if you are looking for a neighbourhood with a greater percentage of prices under the $200k mark you might be better off looking in places like Spring Creek and possibly Manhattan Beach.
Removing Outliers
For my analysis I decided to remove outlier sales. Since I want to predict the price of houses using regression models I believed that it would be harder to get a model that performs well for both normal and outlier pattern sales, the latter of which may include multiple commercial properties (for example the 28 commercial units sold for ±$500 million). I understand that doing this renders my models incapable of generalising to outlier house prices and may 'artificially' improve the performance of my regression models.
def remove_outlier(df, col): q1 = df[col].quantile(0.25) q3 = df[col].quantile(0.75) iqr = q3 - q1 lower_bound = q1 - (1.5 * iqr) upper_bound = q3 + (1.5 * iqr) out_df = df.loc[(df[col] > lower_bound) & (df[col] < upper_bound)] return out_dfhousing_data = remove_outlier(housing_data,"sale_price")
Using the above lines of code, I used the interquartile rate to detect lower and upper bound outlier prices and removed them from my database
Data Clean Up
The Brooklyn house sales database contains 111 columns, a number of these columns contain too many NA values to be of significant value to my analysis. After trying out a few options I opted to drop all columns with 75% or more NA values.
threshold = len(housing_data) * .75housing_data.dropna(thresh = threshold, axis = 1, inplace = True)

I then proceeded to drop columns that did not add any useful information or that contained information that duplicated existing columns.
housing_data = housing_data.drop(['APPBBL','BoroCode','Borough','BBL','price_range','PLUTOMapID','YearBuilt','CondoNo','BuiltFAR','FireComp','MAPPLUTO_F','Sanborn','SanitBoro','Unnamed: 0','Version', 'block','borough','Address','OwnerName','zip_code'],axis=1)
It did not for example make any sense including the Borough columns since all the houses in the dataset are in the same borough and the address an YearBuilt columns where duplications of existing columns.
Cleaning up NA values
After dropping columns consisting largely of NA values, I still had columns that contained a lot of missing data (ranging from a few thousands to over 80 000) I had to decide how I would handle these NA values. For some columns it made more sense to fill in the missing values with the mode (e.g ZipCode, School District, Police Precinct, Sanitation District, X and Y coordinates) because although these are presented in numerical format, they are not quantitative and are essentially categorical values represented by numbers, therefore finding the median would not give me useful information. In other cases it made more sense filling in missing values with 0. For example, if there is a missing value in a column representing the year in which alterations where carried out on a property, it may make more sense assuming no alteration had been carried out. For other categorical columns, I filled the missing data with the modal value of their respective columns and for the rest of the numerical variables I used a mixture of a soft impute imputation and filling missing data using the median value.
#if basement data is missing it might be safer to assume that whether or not the apartment/building is unknown which is represented by the number 5housing_data['BsmtCode'] = housing_data['BsmtCode'].fillna(5)
#Community Area- not applicable or available if Nahousing_data[['ComArea','CommFAR','FacilFAR','FactryArea','RetailArea','ProxCode','YearAlter1','YearAlter2']] = housing_data[['ComArea','CommFAR','FacilFAR','FactryArea','RetailArea','ProxCode','YearAlter1','YearAlter2']].fillna(0)housing_data[['XCoord','YCoord','ZipCode','LotType','SanitDistr','HealthArea','HealthCent','PolicePrct','SchoolDist','tax_class_at_sale','CD','Council']] = housing_data[['XCoord','YCoord','ZipCode','LotType','SanitDistr','HealthArea','HealthCent','PolicePrct','SchoolDist','tax_class_at_sale','CD','Council']].apply(lambda x: x.fillna(x.mode()[0]))
#soft imputefrom fancyimpute import SoftImputefeature_arr = housing_data.drop(['OfficeArea','commercial_units','residential_units','ResArea'],axis=1).select_dtypes(include=[np.number])softimpute = SoftImpute()housing_data2 = pd.DataFrame(softimpute.fit_transform(feature_arr.values),columns=feature_arr.columns,index=feature_arr.index)
#fill in missing values with imputation valueshousing_data = housing_data.fillna(housing_data2)
With the soft impute method, I opted to import the fancy impute library. According to its documentation, Soft impute is based on Spectral Regularization Algorithms for Learning Large Incomplete Matrices. Simply put, this method makes guesses to fill in the missing values, using singular value decomposition calculations at each iteration. It is specifically tailored to handle large data with multiple dimensions-which is the major reason why I opted for this solution. The mechanics behind soft impute are explained in greater detail in the urls I attached to the relevant key phrases.
housing_data = housing_data.apply(lambda x: x.fillna(x.median()) if x.dtype.kind in 'iufc' else x.fillna(x.mode()[0]))
For the rest of the missing data I wrote an if statement to identify the data type of the objects in a column and filling in the values using the modal value in the case of categorical/string/boolean values and the median for numerical /float values.
housing_data['Age of House at Sale'] = housing_data['year_of_sale'] - housing_data['year_built']housing_data = housing_data.drop(['year_of_sale','year_built'],axis=1)
Instead of having two separate columns for the year of sale and year in which the house was built, I created a column that would show the age of the house at the time of sale. I believe this column contains the information that the year of sale and year-built column collectively show. In addition to this, the year of sale information is already shown in the date of sale column (which contains the date, month and year of sale).
Converting categorical to numerical data
A lot of machine learning tools only accept numerical data as input. In order to cater for my categorical columns I wrote a function to create numerical values for each unique strings my categorical columns. I then proceeding to convert these strings to their numerical representations.
#change strings to ints to preprocess for ML algodef strnums(cols): return dict(zip(set(housing_data[cols]),list(range(0,len(set(housing_data[cols]))))))for columns in set(housing_data.select_dtypes(exclude='number')): housing_data[columns] = housing_data[columns].map(strnums(columns))
Baseline Model
For the baseline model I made the assumption that the hypothetical person trying to guess the price of a house would use a central tendency measure, in this case the median to guess the price of a house in the dataset (maybe I should have opted for a linear regression model). The baseline model can be thought of as the common-sense model, ie. what would someone who is not a real estate expert and does not know anything about supervised machine learning or data science use to try and predict the selling price of houses.
from sklearn.dummy import DummyRegressorfrom sklearn.metrics import mean_absolute_errorfrom sklearn.metrics import r2_scorefrom sklearn.model_selection import train_test_splitfeatures = list(housing_data.drop(['sale_price'],axis=1)) y = housing_data.sale_priceX = housing_data[features]X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=100)dummy_median = DummyRegressor(strategy='mean')dummy_regressor = dummy_median.fit(X_train,y_train)dummy_predicts = dummy_regressor.predict(X_test)print("Model Accuracy:", dummy_regressor.score(X_test,y_test)*100)For this I make the assumption that every guess is the median value of sale prices and proceeded to return the accuracy of this model using .score() . This measures the accuracy of the predictions in this model by internally comparing them to the real values.
Model Accuracy: -0.00019362576233472595
In this case no value falls in the median or the mean
print('$',mean_absolute_error(y_test,dummy_predicts))$ 244809.01786117873The average error margin for each prediction is around $244 000.
From trees to forests
I chose to use a regression tree, random forest and gradient boosting to gauge which model would give me the best predictions for this problem.
Decision Trees
 Decision tree in decision making
Decision tree in decision making
A decision tree is a supervised machine learning algorithm that can either be used for classification or regression problems. You can think of it as if, else statements, the algorithm breaks down the dataset into smaller and smaller subsets using the best features (features are predictors). The algorithm often used is known as Classification And Regression Trees (CART). For each subset it calculates the mean squared error (MSE)-this is what I have set as the criterion- and chooses the split that minimises the square loss error. This process stops at a pre-set termination point (maximum depth). This depth should be optimised to reduce the risk of over-fitting and finding the depth with the best predictive capabilities.
Since the decision tree takes random samples and even features in the data when splitting the data, setting the random_state parameters allows me to control the random choices the tree makes to keep the results consistent if I chose to re-run the algorithm
I chose this model because it is fairly easy to understand and kind of resembles the general decision making process.
Random Forest
The reason for the inclusion of this model, ties into how it works. A random forest kind of builds on the regression tree. Random Forest runs an n number of regression trees and then combines them into a single model. The assumption here is that one tree may give us inaccurate predictions but when you run these trees multiple times and combine these predictions you will get predictions closer to the actual values.
Gradient Boosting Regression Tree
With boosting, the concept involves turning a weak learner (features that are not that strong at predicting our outcome) to a strong learner. Boosting does this by identifying weak learners in each regression tree we run, assigning an equal weight to each observation while paying high attention to the distance between the predictions made by the weak learner and the actual values is the error rate of the model. With gradient boosting the model not only tries to reduce the loss function (square loss error in this case) but it also uses the error rate (learnt from observing weak learners) to calculate the steepness of the error function, using this to determine how to change the parameters in the model to reduce error with each iteration. This process is carried out n number of times.
from sklearn.tree import DecisionTreeRegressorfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.ensemble import GradientBoostingRegressormodels = [RandomForestRegressor(n_estimators=200,criterion='mse',max_depth=20,random_state=100),DecisionTreeRegressor(criterion='mse',max_depth=11,random_state=100),GradientBoostingRegressor(n_estimators=200,max_depth=12)]learning_mods = pd.DataFrame()temp = {}#run through modelsfor model in models: print(model) m = str(model) temp['Model'] = m[:m.index('(')] model.fit(X_train, y_train) temp['R2_Price'] = r2_score(y_test, model.predict(X_test)) print('score on training',model.score(X_train, y_train)) print('r2 score',r2_score(y_test, model.predict(X_test))) learning_mods = learning_mods.append([temp])learning_mods.set_index('Model', inplace=True)fig, axes = plt.subplots(ncols=1, figsize=(10, 4))learning_mods.R2_Price.plot(ax=axes, kind='bar', title='R2_Price')plt.show()I played around with my estimates and maximum depth for each model to find the optimal results and created a for loop to run through each model, train my data and making predictions according to each model. I then proceed to plot the R-Squared scores to indicate how good a fit each model is.
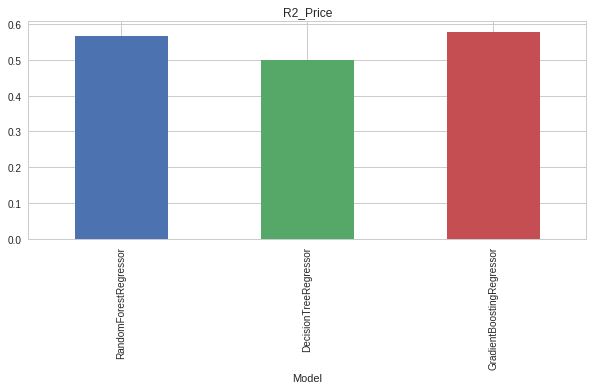
RandomForestRegressorscore on training 0.8163539671493629 r2 score 0.5679147469969195
DecisionTreeRegressorscore on training 0.5514037201337179r2 score 0.4986320564265784
GradientBoostingRegressorscore on training 0.8354890542936946 r2 score 0.5792007036236262
Gradient Boost outperforms both the Random Forest and Regression tree with an accuracy score of 83.5% on training data and about 57.9% on test data not including outlier predictions. The R-squared score is used to explain how well the data fits into the model.
Feature Importance
Not all features are created equally, to further understand the underlying logic of my models I can look at the relative importance each feature has on my model. By doing this I can opt to limit the features my model uses as predictors to predictors that appear to be more important to my regression trees. In theory, this may improve both the accuracy and speed of my models.
regressionTree_imp = model.feature_importances_plt.figure(figsize=(16,6))plt.yscale('log',nonposy='clip')plt.bar(range(len(regressionTree_imp)),regressionTree_imp,align='center')plt.xticks(range(len(regressionTree_imp)),features,rotation='vertical')plt.title('Feature Importance')plt.ylabel('Importance')plt.show()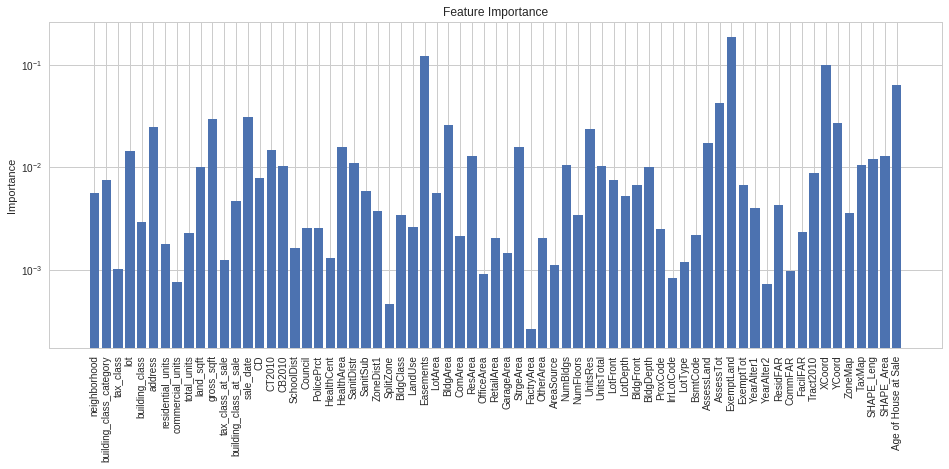 Feature Importance
Feature Importance
From the 69 features in the model, the plot shows a snapshot of features that have the greatest impact on my models. While I could try and optimise my model further by limiting the features used by my models to features that contribute more towards my regression models, I opted to end my analysis here.
If you have any feedback or just want to relish in the aura of my ability to select great dank memes and gifs feel free to reach out on Twitter @Emmoemm
Predicting the price of houses in Brooklyn using Python was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.