Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
A complete overview of a robust library (Scikit-learn) in Python with an example.
Python is one of the most widely used programming languages for Machine Learning, AI, and Deep learning. The popularity of python towards Data science filed is due to its vast library. it provides great open source libraries that help developers to automate their task very easily. One of the most gigantic libraries used by most of the machine learning engineers for Data preprocessing, splitting the dataset for testing and training, and for building the machine learning models is Scikit-Learn: Simple and efficient tools for data mining and data analysis.
Scikit-learn provides a good amount of supervised and unsupervised learning algorithms through a consistent interface. this helps engineers, to build the model very easily in a consistent manner.
Implementation Of Scikit-Learn Library
The library is built upon the SciPy (Scientific Python) that must be installed before you can use Scikit-learn. This stack that includes:
Pandas: Data structures and analysis
NumPy: Base n-dimensional array package
SciPy: Fundamental library for scientific computing
Matplotlib: Comprehensive 2D/3D plotting
IPython: Enhanced interactive console
Sympy: Symbolic mathematics
Features Of Scikit-Learn Library
It provides several features and inbuilt models to reduce development time. the models and features available in Scikit-learn are:
Supervised Learning Models: supports the following models implemented algorithms, which include:
- Linear models
- Classification models
- Support Vector Machines
- Navie Bayes
- Decision trees
Dimensionality Reduction: For reducing the number of attributes in data for summarization, visualization and feature selection such as Principal component analysis.
Cross-Validation: for estimating the performance of supervised models on unseen data.
Feature selection: for identifying meaningful attributes from which to create supervised models.
Parameter Tuning: for getting the most out of supervised models.
Manifold Learning: for summarizing and depicting complex multi-dimensional data.
These are the various features that are available on Scikit-learn library. I want to demonstrate this library with a simple Decision tree classifier.
Implementation Of Decision Tree Classifier Using Scikit-Learn
The Scikit learn library is not only famous for inbuilt machine learning models but also for the inbuilt datasets. In this demonstration example, I’m going to use inbuilt Iris Dataset.
Every Machine Learning model starts with importing the required libraries in the program.
# Importing the required modulesfrom sklearn import datasets # Helps to import required Iris Datasetfrom sklearn import metrics # Helps us to Evaluate the model.from sklearn.tree import DecisionTreeClassifier# Helps us to construct the Model.
After importing the required libraries, we need to load the dataset which is going to train our model.
# Load the dataset from the library.dataset = datasets.load_iris()
Now we need to build a model by selecting the required classifier. In our case, it is the Decision tree classifier.
# The below lines will build the model and fits the data into it.MLModel = DecisionTreeClassifier()MLModel.fit(dataset.data, dataset.target)
After the model is trained we need to test the model against our test dataset to make predictions and to calculate the accuracy and performance of the model.
# Expected values and the predicted values are stored in a variableexpected_value = dataset.targetpredicted_value = MLModel.predict(dataset.data)
Getting the overall metrics for our build model this will be done with the help of Scikit-learn only.
# Summarizing the fitted model.
print(metrics.classification_report(expected_value,predicted_value))print(metrics.confusion_matrix(expected_value,predicted_value))
At last, we are generating the classification report and confusion matrix.
Confusion Matrix: A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known. It allows the visualization of the performance of an algorithm.
Executing the above example produce the following results as shown below.
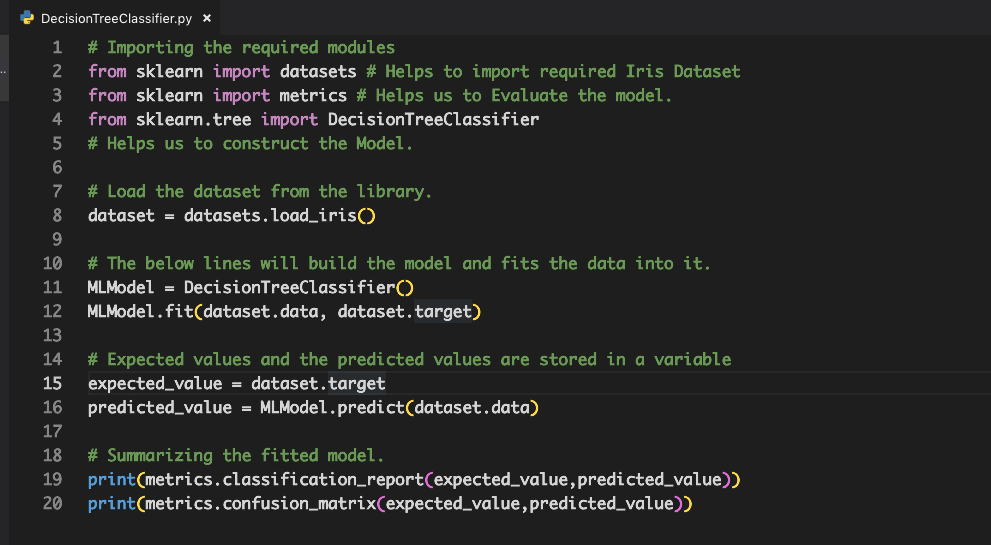 Overall Source Code in a SnapShot
Overall Source Code in a SnapShot Model Output.
Model Output.
Conclusion
The power of Scikit-learn is pretty amazing because we can build a simple model with only 10 lines of code, and there are many more features to explore. It can make our lives a lot easier when compared to the traditional way of building the model.
Check out My Twitter, Github, and Facebook. 🙂
Scikit-Learn Library for Machine Learning in a Nutshell was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.