Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In many applications, speed has a greater value than quality. When a BRKNG article is out, a recommendation system doesn’t have time to come up with perfectly relevant suggestions. The traffic spike occurs in the first minutes. Here is an idea of how to cope with the situation.
Nowadays it’s rather hard to find a news website that wouldn’t make a try to keep your attention by means of some recommendation system.
If you happen to read an article anywhere on the internet—the “read next”, “most read”, “trending” or something of the like will inevitably meet you below. At times we still see editor’s digest — the case when recommended articles don’t change regardless of the context. The more advanced would use tags, content-based or another kind of handcrafted similarity. But when a person reads of a today’s fire accident it doesn’t necessarily mean that “fire” or “accident” characterizes his or her interest. It could be true for say 11.3% but other news from today could be more interesting than another fire accident from a month ago, let’s say with a probability of 24.6%, and the rest of probable interest is a complex combination of thoughts and feelings formed by informational background over the past three days.
Of course, one could somehow understand and measure the influence of all the possible factors and come up with a list of very precise coefficients for a ranking function, but tomorrow the world is gonna be different. An empirical study shows that collaborative filtering of any sort is way more efficient in making recommendations. That is, we should never try to interpret the collective mind into a human-readable representation. The modern recommendation system should look not for keywords and dates, but for behavioral patterns. The simple and proven method to be efficient is to rely on the cosine similarity of the articles.
In order to use cosine similarity, you have to represent articles as vectors of visits. For simplicity let the Nth coefficient be 1 when the Nth reader has visited a given article and 0 otherwise. When exploring multiple articles, you can stack those vectors into a matrix where each row represents an article and each column represents a reader. If you pick a window in an access log of a website you can represent it as follows.
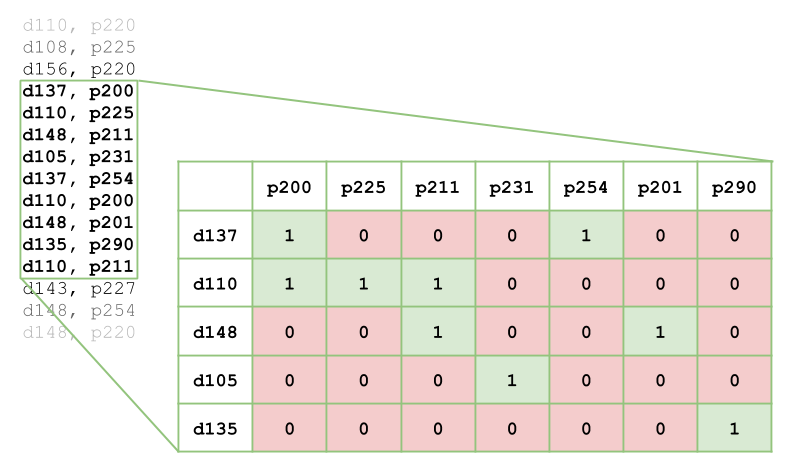 d — document, p — person (which are more general terms for an article and a reader)
d — document, p — person (which are more general terms for an article and a reader)
Now, to know the cosine similarity between each pair of articles you can use the following approach.
The resulting symmetric matrix has a shape of M by M where M is the number of articles. Each coefficient denotes a measure of similarity between i-th and j-th article. Needless to say, when i = j the coefficient is 1 as this is the similarity of an article to itself.
The above example is a kind of batch processing. That is, when you load a decent piece of raw input data, make calculations and store a result, they can be retrieved later on when recommendations are requested. This approach is widely used in recommendation systems as it enables you to use a more complex data representation and a more precise algorithm. It works pretty well in the applications where new publications have a lower frequency and a longer lifecycle — such as an online store or an entertainment platform. But when it comes to a news website an intermittent operation becomes a significant problem.
Imagine a viral publication that’s being visited by thousands of people within a few minutes. What if such a wave happens to come in between duty cycles of your recommendation system that runs a batch every 10 minutes? To take full advantage of the peak attendance you have to recommend something to those people in order to make them stay. When you try to increase the frequency of batch processing while having limited computational power, you likely need to decrease the size of a batch, which in turn reduces the quality of the outcome and still doesn’t fully eliminate the negative effect of intermittency. So, how do you make a recommendation system for a news website work continuously?
The key idea is to always keep the document/person matrix in memory, to fill it with data as it comes and to perform the calculation on demand. At the same time, we still would want to have control over the size of the matrix. Hence, the matrix must contain only the most important data at any given moment in time. As if the batch was loaded every time when a request for recommendations has been dispatched. What comes to mind is to make use of some cache replacement policy.
Imagine we have a pouring input stream of document_id, person_id pairs. When the next pair arrives we put its document_id into Cache1 and person_id into Cache2. When a hit occurs we adjust the corresponding cache in accordance with the policy and assign a corresponding coefficient in the matrix. And for a case of a miss, we replace the least important (e.g. the least recent) record in the cache and reinitialize the corresponding row or column in the matrix with all zeros except for the intersection of the pair. The GIF that’s worth a thousand words is shown below.
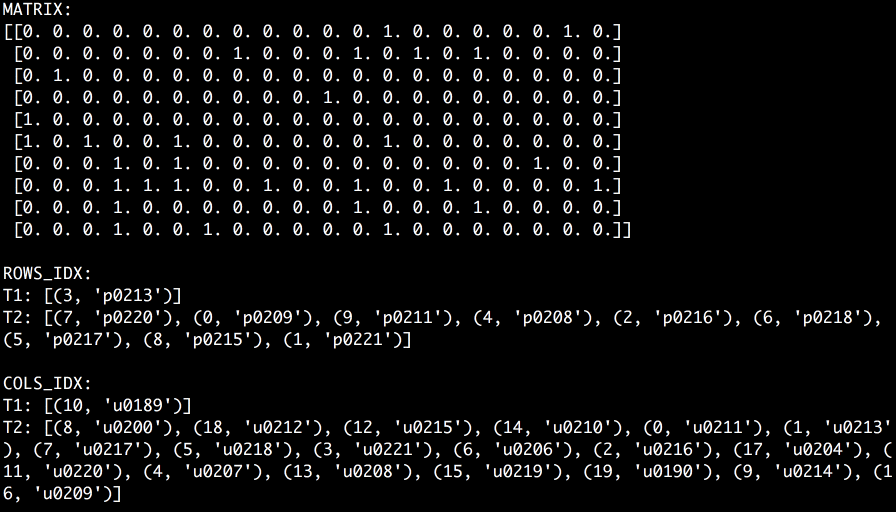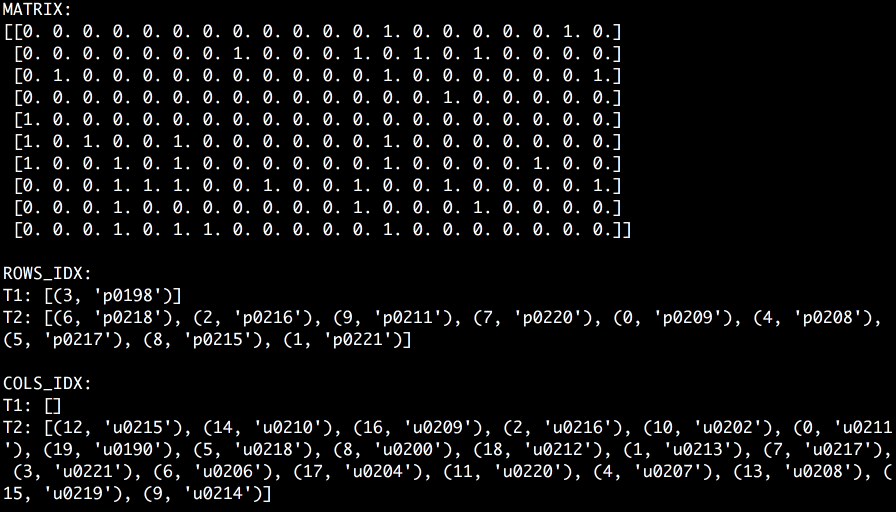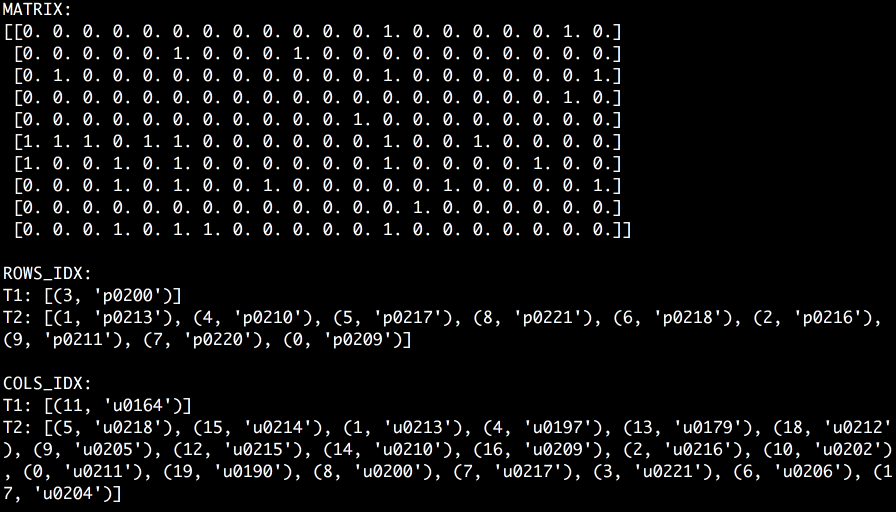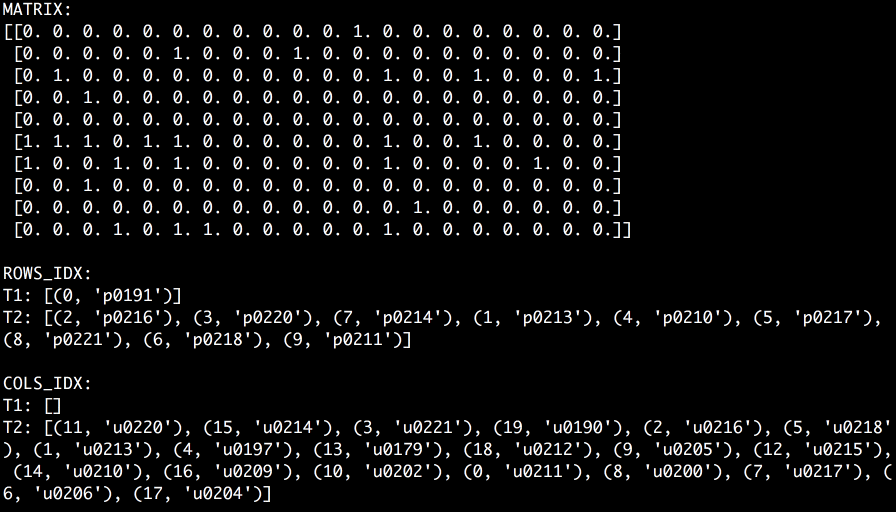
In this example, I use the Adaptive Replacement Cache algorithm. This algorithm accounts for both frequency and recency of elements that are being cached by learning from an eviction history. The ratio of the most frequent elements to the most recent elements is adaptive and is the core knowledge of the algorithm. It helps to keep only the most important elements in memory, that is, such elements that are likely to be accessed again in the near future. The key feature of the implementation that I use is that every record in the cache is assigned a unique ID taken from the range of 0 to N - 1, where N is the maximum number of records in the cache. These IDs don’t tell us anything about the order of records but just are guaranteed to be unique across a cache instance. Thus, IDs can be used as indexes of rows and columns in the matrix. When a record is evicted, ID is reused and we know which row or column has to be reinitialized. Now we have a “Rolling Feature Matrix”. Meaning that it contains a sliding batch of input data ready to be used for the calculation of recommendations in the real-time. Of course, this approach may have many more applications. I’m just using a recommendation system to give you an idea.
Implementation Nuances
Use lil_matrix to make the calculation faster while preserving the efficiency of mutation (sparsity change), drop unneeded columns before performing a calculation of recommendations for a certain document. That is, slice out all columns where the corresponding row has zeros.
In the case when you have a 2k by 2k matrix with something about 10k of nonzero values (which is a sufficient amount of data in many situations) the above code runs hundreds of times per second within a single thread on any modern CPU making this approach suitable for a real-time application.
To make my point I’ve implemented Recom.live, the recommendation system that takes advantage of the “Rolling Feature Matrix”. This is a production-ready real-time recommendation system. You can install and run it in a docker container. Please check out this repository, containing a Dockerfile and instructions. In short, installation is as simple as:
This will start a UDP server (default port is 5005). You can start pouring document_id, person_id pairs into it and retrieving recommendations out of it by providing the same context (the pair of document_id, person_id). The API is very simple, although to make it even simpler, I’ve written a tiny client library in python.
Under the load, Recom.live is holding 700 record/recommend requests per second while running on Intel Core-i5 CPU. Having a default shape of the matrix (which is 2000 X 2000) Recom.live server consumes about 100 Mb of RAM. Docker image is built from debian:stretch-slim and takes about 350 Mb of disk space. All in all, it definitely isn’t going to bring your servers down.
So, everyone is welcome to use, leave feedback and contribute to the development of Recom.live. Have a great day/weekend/life and never hesitate to reach out!
Real-time Recommendation System: Rolling Feature Matrix was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.