Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Failing To Succeed And Succeeding At Failing
TLDR: Your micro-services are vulnerable to unexpected failure if services they depend on fail in some way (and you don’t handle it).
Fault test your HTTP micro-services using a “Chaos Proxy”.
Here’s one I made earlier:
AndyMacDroo/clusterf-chaos-proxy
Chaos Engineering — What Is It?
 Netflix’s Chaos Monkey is mostly responsible for popularising the concept of Chaos Engineering.
Netflix’s Chaos Monkey is mostly responsible for popularising the concept of Chaos Engineering.
Chaos Engineering is a great idea: build an automated solution/tool to randomly attempt to break a system in some way; ultimately so as to learn how the system behaves in such situations. Then you can use your newfound knowledge to find ways to make the system more fault tolerant during these failure conditions in the future.
What The Heck Is A ‘Chaos Proxy’?
A ‘Chaos Proxy’ is a service which your micro-services can connect to.
It routes traffic to real destination micro-services and returns responses back to the micro-services through the proxy — but does so in a very unreliable way.
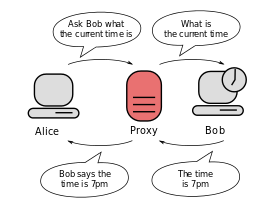
Through the proxy, requests are randomly delayed and/or randomly fail in unexpected ways — all for the sole purpose of helping you understand how the micro-service responds to these various failure conditions.
…Seriously, Why Would Anyone Want An Unreliable HTTP Proxy?
Everything fails eventually. Everything.

Accept it and embrace failure. Design for failure. Succeed at failing.
Micro-services often communicate with other services via REST and HTTP. How do your micro-services cope when the services they depend on inevitably fail in some unpredictable way?
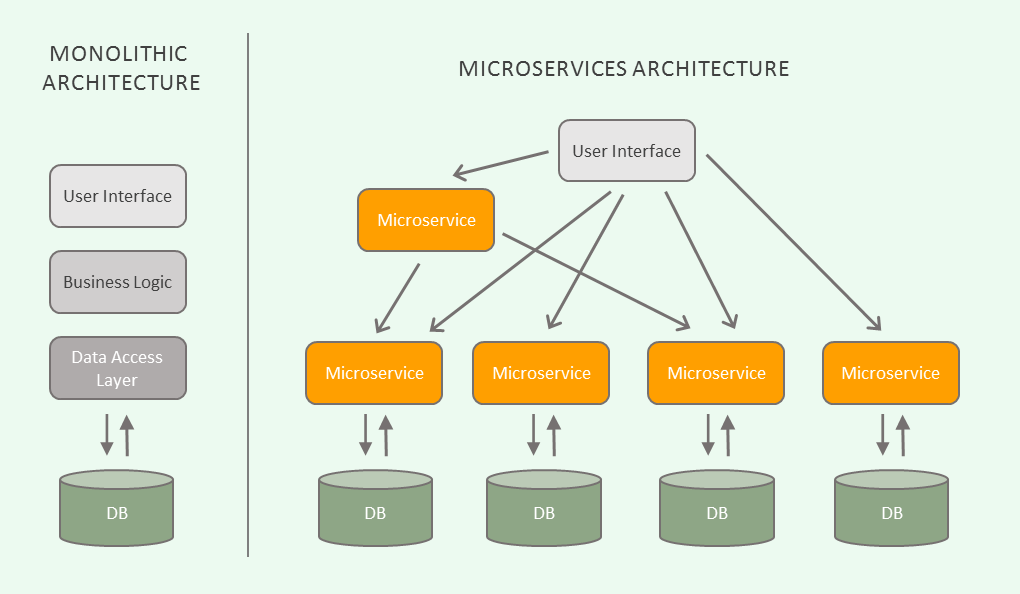 Courtesy of: https://blog.algorithmia.com/introduction-to-microservices/
Courtesy of: https://blog.algorithmia.com/introduction-to-microservices/
Your micro-services are vulnerable to unexpected failure if services they depend on fail (and you haven’t accounted for the failure or defined how your service should behave).
No Really… Why Is This Useful?
Recently I was investigating a JDBC connection leak in a micro-service.
With modern frameworks abstracting away JDBC operations, connection leaks shouldn’t really happen these days, but alas there was a connection leak…
I wanted to assess how resilient the micro-service (A) was to failures and delays in another micro-service (B) that it depended upon.
I needed a way to simulate periodic failures and delays in micro-service ‘B’ while I performed requests and automated regression tests locally against micro-service ‘A’.
I could access micro-service ‘B’ on a remote environment but because of various constraints, I couldn’t run ‘B’ up locally and try to modify it to emit failures.
I couldn’t really find something that existed that was lightweight, reasonably easy to set up and that accomplished what I had hoped to accomplish.
After some fiddling around, the first iteration of ClusterF*** was born!
Thanks to ClusterF*** (and handy-dandy VisualVM), I was able to identify that with sufficiently delayed responses from micro-service ‘B’ — the JDBC connections in micro-service ‘A’ would stack up and stick around for as long as the HTTP request was active — even if the JDBC transaction had actually long since committed.
With the cause known, this opened up a range of possible solutions for the issue (and an easy way to test their effectiveness through ClusterF***) — e.g:
- Implement controlled timeout on request from ‘A’ to ‘B’.
- Implement timeout of JDBC connections and return to the connection pool.
- Make elements of processing asynchronous so the request thread exits quicker.
ClusterF***
 https://github.com/AndyMacDroo/clusterf-chaos-proxy
https://github.com/AndyMacDroo/clusterf-chaos-proxy
The premise is simple:
- Front the HTTP services your micro-service depends on with ClusterF***.
- Point the micro-service you’re testing at ClusterF***.
- Configure ClusterF*** and run it.
- Use your micro-service (fire requests at it).
- Watch the chaos unfold🔥 🔥 🔥 (through monitoring logs or through application behaviour).
- (Optional) Learn from the chaos and implement changes to improve the resilience of your micro-service.
- REPEAT.
At the time of first putting ClusterF*** together, I wasn’t really aware of the concept of a ‘Chaos Proxy’ or that others had beat me to the idea — but I decided to finish the first iteration of ClusterF*** off because as they say:
It doesn’t matter if you’re first or last, just so long as you have the cooler name…
Getting Started
ClusterF*** is on DockerHub — to install simply:
docker pull andymacdonald/clusterf-chaos-proxy
And then configure a docker-compose file with the destination service details — e.g if your ‘B’ service runs on http://10.0.0.231:8098:
version: "3.7"services: user-service-chaos-proxy: image: andymacdonald/clusterf-chaos-proxy environment: JAVA_OPTS: "-Dchaos.strategy=RANDOM_HAVOC -Ddestination.hostProtocolAndPort=http://10.0.0.231:8098" ports: - "8080:8080"
Configure a chaos strategy as per the project’s README.md:
NO_CHAOS - Request is simply passed through
DELAY_RESPONSE - Requests are delayed but successful (configurable delay)
INTERNAL_SERVER_ERROR - Requests return with 500 INTERNAL SERVER ERROR
BAD_REQUEST - Requests return with 400 BAD REQUEST
RANDOM_HAVOC - Requests generally succeed, but randomly fail with random HTTP status codes and random delays
Then simply:docker-compose up
Once the application is up — you can point the micro-service(s) you want to test at your ClusterF*** instances (instead of the real destination services). Then just fire up the micro-service and start testing and using it.
Depending on the strategy you’ve picked — ClusterF*** will affect the strategy against the requests you send to it.
Probably the most useful strategies are RANDOM_HAVOC and DELAY_RESPONSE — but you still might find the others useful.
More features will be added in the future with more configurable options!
Suggestions
I’d appreciate if you’d give some feedback on the project and if you find it useful.
If you have any suggestions for ClusterF***, could you add them to the project’s issues section on Github?
Thanks 👍
Thanks for reading! 😃
Hopefully, you’ve enjoyed this article and the introduction to the concept of a ‘Chaos Proxy’.
Although I’ve shamefully plugged my own personal project here, the concept is incredibly simple to implement. Feel free to take my project and fork it or just make your own implementation!
For a decent list of resources around Chaos Engineering, take a stop by this repo:
dastergon/awesome-chaos-engineering
Chaos Engineering: Chaos Testing Your HTTP Micro-Services was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.