Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Pytorch is a deep learning framework; a set of functions and libraries which allow you to do higher-order programming designed for Python language, based on Torch. Torch is an open-source machine learning package based on the programming language Lua. It is primarily developed by Facebook’s artificial-intelligence research group and Uber’s Pyro probabilistic programming language software is built on it.
PyTorch is more “pythonic” and has a more consistent API. It also has native ONNX model exports which can be used to speed up inference. PyTorch shares many commands with numpy, which helps in learning the framework with ease.
At its core, PyTorch provides two main features:
- An n-dimensional Tensor, similar to Numpy but can run on GPUs
- Automatic differentiation for building and training neural networks
If you’re using anaconda distribution, you can install the Pytorch by running the below command in the anaconda prompt.
conda install pytorch-cpu torchvision-cpu -c pytorch
The rest of the article is structured as follows:
- What is Colab, Anyway?
- Setting up GPU in Colab
- Pytorch Tensors
- Simple Tensor Operations
- Pytorch to Numpy Bridge
- CUDA Support
- Automatic Differentiation
- Conclusion
If you want to skip the theory part and get into the code right away,
Niranjankumar-c/DeepLearning-PadhAI
Colab — Colaboratory
Google Colab is a research tool for machine learning education and research. It’s a Jupyter notebook environment that requires no setup to use. Colab offers a free GPU cloud service hosted by Google to encourage collaboration in the field of Machine Learning, without worrying about the hardware requirements. Colab was released to the public by Google in October 2017.
Getting Started with Colab
- Sign in with your Google Account
- Create a new notebook via File -> New Python 3 notebook or New Python 2 notebook
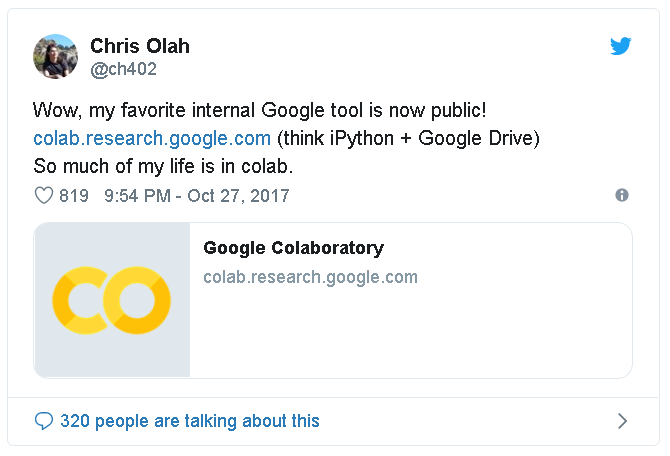
You can also create a notebook in Colab via Google Drive
- Go to Google Drive
- Create a folder of any name in the drive to save the project
- Create a new notebook via Right click > More > Colaboratory
To rename the notebook, just click on the file name present at the top of the notebook.

Setting up GPU in Colab
In Colab, you will get 12 hours of execution time but the session will be disconnected if you are idle for more than 60 minutes. It means that for every 12 hours Disk, RAM, CPU Cache and the Data that is on our allocated virtual machine will get erased.
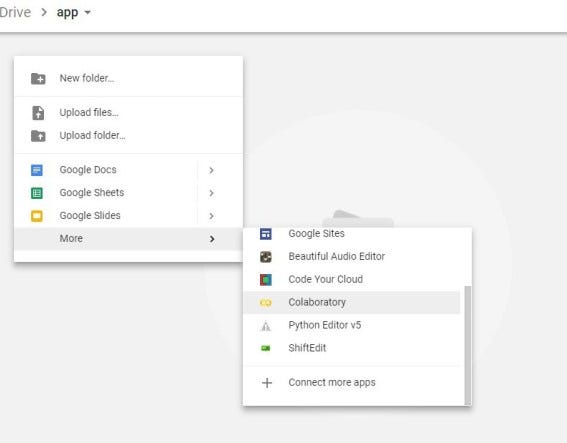
To enable GPU hardware accelerator, just go to Runtime -> Change runtime type -> Hardware accelerator -> GPU
Pytorch — Tensors
Numpy based operations are not optimized to utilize GPUs to accelerate its numerical computations. For modern deep neural networks, GPUs often provide speedups of 50x or greater. So, unfortunately, numpy won’t be enough for modern deep learning. This where Pytorch introduces the concept of Tensor. A Pytorch Tensor is conceptually identical to an n-dimensional numpy array. Unlike the numpy, PyTorch Tensors can utilize GPUs to accelerate their numeric computations
Let’s see how you can create a Pytorch Tensor. First, we will import the required libraries. Remember that torch, numpy and matplotlib are pre-installed in Colab’s virtual machine.
import torch import numpy import matplotlib.pyplot as plt
The default tensor type in PyTorch is a float tensor defined as torch.FloatTensor. We can create tensors by using the inbuilt functions present inside the torch package.
## creating a tensor of 3 rows and 2 columns consisting of ones >> x = torch.ones(3,2) >> print(x) tensor([[1., 1.], [1., 1.], [1., 1.]])
## creating a tensor of 3 rows and 2 columns consisting of zeros >> x = torch.zeros(3,2) >> print(x) tensor([[0., 0.], [0., 0.], [0., 0.]])
Creating a tensor by random initialization
To increase the reproducibility, we often set the random seed to a specific value first. >> torch.manual_seed(2) #generating tensor randomly >> x = torch.rand(3, 2) >> print(x) #generating tensor randomly from normal distribution >> x = torch.randn(3,3) >> print(x)
Simple Tensor Operations
Slicing of Tensors
You can slice PyTorch tensors the same way you slice ndarrays
#create a tensor >> x = torch.tensor([[1, 2], [3, 4], [5, 6]]) >> print(x[:, 1]) # Every row, only the last column >> print(x[0, :]) # Every column in first row >> y = x[1, 1] # take the element in first row and first column and create a another tensor >> print(y)
Reshape Tensor
Reshape a Tensor to a different shape
>> x = torch.tensor([[1, 2], [3, 4], [5, 6]]) #(3 rows and 2 columns) >> y = x.view(2, 3) #reshaping to 2 rows and 3 columns
Use of -1 to reshape the tensors
-1 indicates that the shape will be inferred from previous dimensions. In the below code snippet x.view(6,-1) will result in a tensor of shape 6x1 because we have fixed the size of rows to be 6, Pytorch will now infer the best possible dimension for the column such that it will be able to accommodate all the values present in the tensor.
>> x = torch.tensor([[1, 2], [3, 4], [5, 6]]) #(3 rows and 2 columns) >> y = x.view(6,-1) #y shape will be 6x1
Mathematical Operations
#Create two tensors >> x = torch.ones([3, 2]) >> y = torch.ones([3, 2]) #adding two tensors >> z = x + y #method 1 >> z = torch.add(x,y) #method 2 #subtracting two tensors >> z = x - y #method 1 >> torch.sub(x,y) #method 2
In-place Operations
In Pytorch all operations on the tensor that operate in-place on it will have an _ postfix. For example, add is the out-of-place version, and add_ is the in-place version.
>> y.add_(x) #tensor y added with x and result will be stored in y
Pytorch to Numpy Bridge
Converting a Pytorch tensor to a numpy ndarray is very useful sometimes. By using .numpy() on a tensor, we can easily convert tensor to ndarray.
>> x = torch.linspace(0 , 1, steps = 5) #creating a tensor using linspace >> x_np = x.numpy() #convert tensor to numpy >> print(type(x), type(x_np)) <class 'torch.Tensor'> <class 'numpy.ndarray'>
To convert numpy ndarray to pytorch tensor, we can use .from_numpy() to convert ndarray to tensor.
>> a = np.random.randn(5) #generate a random numpy array >> a_pt = torch.from_numpy(a) #convert numpy array to a tensor >> print(type(a), type(a_pt)) <class 'numpy.ndarray'> <class 'torch.Tensor'>
During the conversion, Pytorch tensor and numpy ndarray will share their underlying memory locations and changing one will change the other.
CUDA Support
To check how many CUDA supported GPU’s are connected to the machine, you can use the code snippet below. If you are executing the code in Colab you will get 1, that means that the Colab virtual machine is connected to one GPU. is used to set up and run CUDA operations. It keeps track of the currently selected GPU.
>> print(torch.cuda.device_count()) 1
If you want to get the name of the GPU Card connected to the machine:
>> print(torch.cuda.get_device_name(0)) Tesla T4
The important thing to note is that we can reference this CUDA supported GPU card to a variable and use this variable for any Pytorch Operations. All CUDA tensors you allocate will be created on that device. The selected GPU device can be changed with a torch.cuda.device context manager.
#Assign cuda GPU located at location '0' to a variable >> cuda0 = torch.device('cuda:0') #Performing the addition on GPU >> a = torch.ones(3, 2, device=cuda0) #creating a tensor 'a' on GPU >> b = torch.ones(3, 2, device=cuda0) #creating a tensor 'b' on GPU >> c = a + b >> print(c) tensor([[2., 2.], [2., 2.], [2., 2.]], device='cuda:0')As you can see from the above code snippet the tensors are created on GPU and any operation you do on these tensors will be done on GPU. If you want to move the result to CPU you just have to do .cpu()
#moving the result to cpu >> c = c.cpu() >> print(c) tensor([[2., 2.], [2., 2.], [2., 2.]])
Automatic Differentiation
In this section, we will discuss the important package called automatic differentiation or autograd in Pytorch. The autograd package gives us the ability to perform automatic differentiation or automatic gradient computation for all operations on tensors. It is a define-by-run framework, which means that your back-propagation is defined by how your code is run.
Let’s see how to perform automatic differentiation by using a simple example. First, we create a tensor with requires_grad parameter set to True because we want to track all the operations performing on that tensor.
#create a tensor with requires_grad = True >> x = torch.ones([3,2], requires_grad = True) >> print(x) tensor([[1., 1.], [1., 1.], [1., 1.]], requires_grad=True)
Perform a simple tensor addition operation.
>> y = x + 5 #tensor addition >> print(y) #check the result tensor([[6., 6.], [6., 6.], [6., 6.]], grad_fn=<AddBackward0>)
Because y was created as a result of an operation on x, so it has a grad_fn. Perform more operations on y and create a new tensor z.
>> z = y*y + 1 >> print(z) tensor([[37., 37.], [37., 37.], [37., 37.]], grad_fn=<AddBackward0>) >> t = torch.sum(z) #adding all the values in z >> print(t) tensor(222., grad_fn=<SumBackward0>)
Back-Propagation
To perform back-propagation, you can just call t.backward()
>> t.backward() #peform backpropagation but pytorch will not print any output.
Print gradients d(t)/dx.
>> print(x.grad) tensor([[12., 12.], [12., 12.], [12., 12.]])
x.grad will give you the partial derivative of t with respect to x. If you are able to figure out how we got a tensor with all the values equal to 12, then you have understood the automatic differentiation. If not don't worry just follow along, when we execute t.backward() we are calculating the partial derivate of t with respect to x. Remember that t is a function of z, which in turn is a function of x.
d(t)/dx = 2y * 1 at x = 1 and y = 6, where y = x + 5
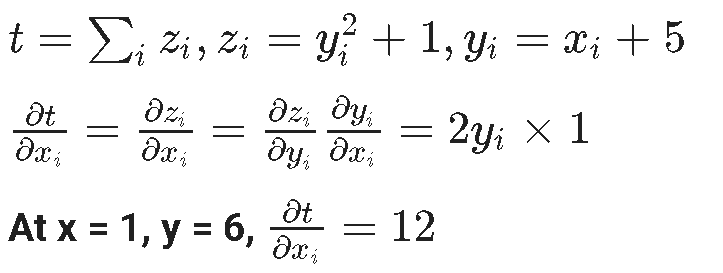
The important point to note is that the value of the derivative is calculated at the point where we initialized the tensor x. Since we initialized x at a value equal to one, we get an output tensor with all the values equal to 12.
The entire code discussed in the article is present in the Kaggle Kernel. Feel free to fork it or download it. The best part is that you can directly run the code in Kaggle Kernel once you fork it, don’t need to worry about installing the packages.
If Colab is your jam, click here to execute the code directly and get your hands dirty.
Niranjankumar-c/DeepLearning-PadhAI
Conclusion
In this post, we briefly looked at the Pytorch & Google Colab and we also saw how to enable GPU hardware accelerator in Colab. Then we have seen how to create tensors in Pytorch and perform some basic operations on those tensors by utilizing CUDA supported GPU. After that, we discussed the Pytorch autograd package which gives us the ability to perform automatic gradient computation on tensors by taking a simple example. If you have any issues or doubts while implementing the above code, feel free to ask them in the comment section below or send me a message in LinkedIn citing this article.
Recommended Reading
- Deep Learning Best Practices: Activation Functions & Weight Initialization Methods — Part 1
- Demystifying Different Variants of Gradient Descent Optimization Algorithm
In my next post, we will discuss how to implement the feedforward neural network using Pytorch (nn.Functional, nn.Parameters). So make sure you follow me on medium to get notified as soon as it drops.
Until then Peace :)
NK.
Author Bio
Niranjan Kumar is Retail Risk Analyst Intern at HSBC Analytics division. He is passionate about Deep learning and Artificial Intelligence. He is one of the top writers at Medium in Artificial Intelligence. You can find all of Niranjan’s blog here. You can connect with Niranjan on LinkedIn, Twitter and GitHub to stay up to date with his latest blog posts.
I am looking for opportunities either full-time or freelance projects, in the field of Machine Learning and Deep Learning. If there are any relevant opportunities, feel free to drop me a message on LinkedIn or you can reach me through email as well. I would love to discuss.
Originally published at https://www.marktechpost.com on June 9, 2019.
Getting Started With Pytorch In Google Collab With Free GPU was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.