Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Neural Style Transfer with my face and various other styles.
Neural Style Transfer with my face and various other styles.
It’s currently an arms race in the tech scene right now with Deep Learning and Artificial Intelligence already the next industry-grade buzzword. Everyone’s looking to make the next big commercial success with a successful and innovative application of Artificial Intelligence.
One such breakthrough is the use of deep learning neural networks to mathematically separate the content and style of images. What naturally entails is the idea of taking the content of one image and the style of another, and merging them both into one image. This idea was successfully implemented in 2015 by Gatys. et al in their paper “A Neural Algorithm of Artistic Style”.
Since then, there have been many insights and improvements of the base idea. Modern iterations of the algorithm are now known as neural style transfer and have progressed much since its inception in 2015. You can read more about the improvements on this paper here.
 Image A provides the content. Image B is the final result, taking the semantic contents from Image A and the style from the smaller image.The core idea behind transferring styles is to take two images, say, a photo of a person, and a painting, and synthesize an image that simultaneously matches the semantic content representation of the photograph and the style representation of the respective piece of art.
Image A provides the content. Image B is the final result, taking the semantic contents from Image A and the style from the smaller image.The core idea behind transferring styles is to take two images, say, a photo of a person, and a painting, and synthesize an image that simultaneously matches the semantic content representation of the photograph and the style representation of the respective piece of art.
As the statement above suggests — we’re going to have mathematically quantify both the style and content representations of images. Using a blank or randomly generated image (a.k.a. a pastiche), we progressively match it with the desired style and content representation.
So how exactly does Deep Learning come into play here? What does it do to be able to separate style and content from images — something even people sometimes struggle to discern.
Evidently, Neural Networks used for Deep Learning are really good at coming up with high and low level representations of the features of an image. To visualize it — let’s take a look at the image of the CNN.
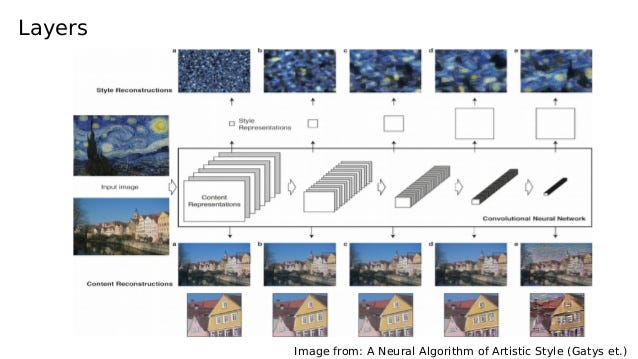 Style and content representations taken at each layer of a Neural Network.
Style and content representations taken at each layer of a Neural Network.
Investigating the feature representations at each layer of the network, you’ll see that each layer progressively produces an abstract concept of either the style (top row of images) and semantic content (the bottom row of images).
In a Convolutional Neural Network (CNN), each layer serves to further abstract the pixel representations of the image we feed it with. Initially, we’ll feed a CNN with an image. But the CNN doesn’t see this image as an image the way we humans do, instead it looks at an image as a matrix of values (more accurately a tensor).
 A matrix representation of the image of the letter a. Pixel values closer to 1 correspond to colors closer to black white values closer to 0 correspond to a lighter hue. Image taken from http://pippin.gimp.org/image_processing/chap_dir.html
A matrix representation of the image of the letter a. Pixel values closer to 1 correspond to colors closer to black white values closer to 0 correspond to a lighter hue. Image taken from http://pippin.gimp.org/image_processing/chap_dir.html
At each layer, a kernel is applied to a patch of the image, moving across the entire image eventually generating an intermediary vector representation of the image. While these generated vectors might not actually mean anything, they allow us to capture the characteristics of the image. You can check out this post for an in-depth visualizing of how a CNN does this.
Naturally, these images are by no means a definitive definition of what style and content truly are, but this is how the neural network perceives it to be so.
Now we’ve got a rough idea of where the abstract characteristics of an image can be found (the vector representations in-between layers). But how do we actually get them out of the CNN?
This is where the key contributions of the paper we spoke of earlier come into play.
The paper’s work was based on a popular and powerful architecture (at the time) dubbed VGG which won the 2014 ImageNet Classification challenge.
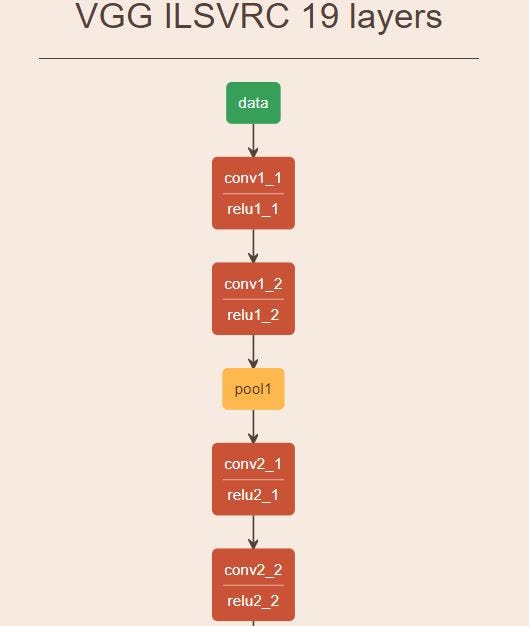 Layers of the VGG19 neural network, taken from https://ethereon.github.io/netscope/#/gist/3785162f95cd2d5fee77
Layers of the VGG19 neural network, taken from https://ethereon.github.io/netscope/#/gist/3785162f95cd2d5fee77
And in this architecture, the intermediary vectors specifically at layers “conv4_2” best represent the semantic content of the image. While style is best represented by a combination of features from the following layers: “conv1_1”, “conv2_1”, “conv3_1”, “conv4_1” and “conv5_1”. How did we come to that specific selection of layers, you ask? It’s really just trial and error.
 Image taken from A Neural Algorithm for Artistic Style. The image structures captured by the style representations increase in size and complexity when including style features from higher layers of the network. This can be explained by the increasing receptive field sizes and feature complexity along the network’s processing hierarchy.
Image taken from A Neural Algorithm for Artistic Style. The image structures captured by the style representations increase in size and complexity when including style features from higher layers of the network. This can be explained by the increasing receptive field sizes and feature complexity along the network’s processing hierarchy.
The idea is that the further down you get in the neural network (and the closer towards classifying objects), the more the feature vector represents the image’s semantic content. Whereas layers higher in the network are able to better capture the image’s style.
Now that we have the style and content representations figured out, we need a way to iteratively match a randomly generated white noise image (our pastiche) with the representations.
 A randomly generated white noise image, which we will iteratively match to the style and content representations.To visualize the image information that is encoded at different layers of the hierarchy we perform gradient descent on a white noise image to find another image that matches the feature responses of the original image.
A randomly generated white noise image, which we will iteratively match to the style and content representations.To visualize the image information that is encoded at different layers of the hierarchy we perform gradient descent on a white noise image to find another image that matches the feature responses of the original image.
Hence we define a squared-error loss between the content representation and our pastiche:
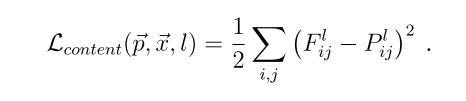 The content loss
The content loss
Where vector p is the original image, vector x the image that is generated and P_l and F_l their respective feature representations in layer l.
From which the gradient w.r.t. to the generated image can be computed using standard error back-propagation. Therefore we can progressively update the random white noise image until it gives the same response in the “conv4_2” layer as the image we want to get semantic content from.
Style however isn’t as straight-forward. We first build a style representationthat computes the correlations between the different filter responses. This is done with the Gram Matrix:
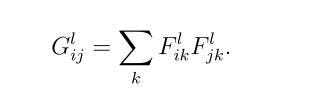
where G^l_ij is the inner product between the vectorized features i and j in layer l. More information on why a Gram Matrix captures the style information can be found on this paper.
By minimizing the mean-squared distance between the entries of the Gram matrix from the original image and the Gram matrix of the image to be generated, we can use gradient descent from a white noise image to find another image that matches the style representation of the original image.
The loss for style is defined as:
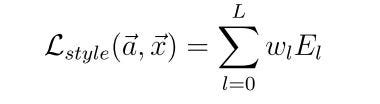
Where E_l is:
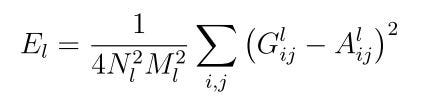
And G and A are the Gram Matrix representations for style of the original image and the generated image respectively in layer l. The gradients can then be computed using standard error back-propagation similar to the content representation above.
We now have all the ingredients we need to generate an image, given an image we want to learn the style from and an image we want to learn the content from.
To generate the images that mix the content of a photograph with the style of a painting we jointly minimize the distance of a white noise image from the content representation of the photograph in one layer of the network and the style representation of the painting in a number of layers of the CNN.
We minimize the following loss function:
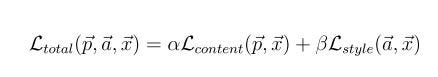
Where alpha and beta are the weights used to determine the overall contributions during the construction of the new image.
Even though this article was written in 2018, the technology described is not new, and has been around for a number of years already.
Indeed, there are already a huge number of improvements and modifications done to the existing model that hugely ramps up many of the aspects of it’s performance, such as increasing the speed of which style transfer is done, reducing the loss to generate better images, making art (this was made by the original authors of the paper) and many more.
What interests me the most is the fact that something I once perceived to be abstract and un-quantifiable — that is the abstract style and content of an image — can now be represented mathematically. Naturally, this makes one wonder if the same thing can be done for other abstract qualities. Not just for images but all forms of mediums, be they videos or text.
What if abstract concepts like emotions, motive and plot can be quantified too? What then will we do with these? It’s exciting times we live in I can’t wait to see what more technology and AI can bring to our culture.
Find this useful? Feel free to smash that clap and check out my other works. 😄
James Lee is an AI Research Fellow at Nurture.AI. A recent graduate from Monash University in Computer Science, he writes about on Artificial Intelligence and Deep Learning. Follow him on Twitter @jamsawamsa.
Learning Artistic Styles from Images was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.