Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
With some RabbitMQ specifics
After I have identified service boundaries (check an example of this approach here), it’s time to talk about concrete steps that I take in my event-driven systems and some things to keep in mind.
Higher-level mental implementation model
As I already mentioned, the mental implementation model of almost any domain I’m involved into looks like that:
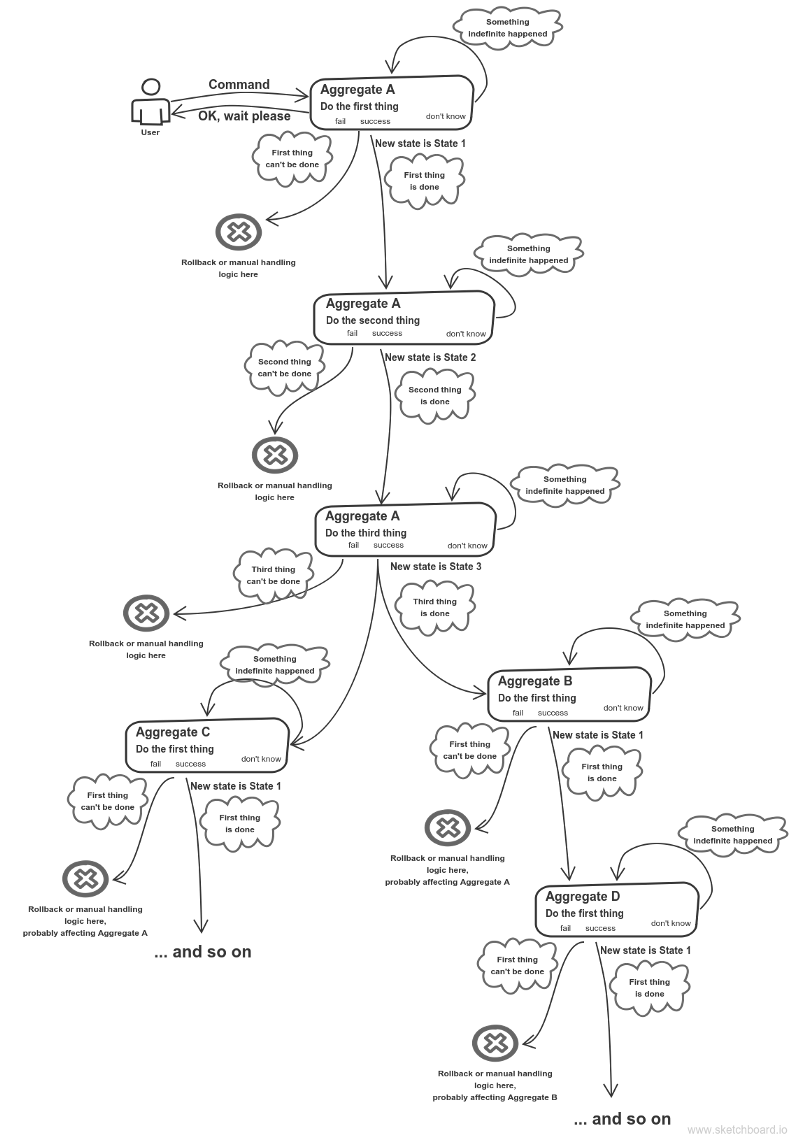 My basic implementation model — Sagas interaction
My basic implementation model — Sagas interaction
So I need to define operations in such a way that they could be naturally retried in case something went wrong the first time.
Why so many arrows?
I don’t want my whole business-process (e.g., the one depicted on “Transaction saga in Reconciliation service” pic) to reside within one request and /or transaction scope. There are at least two reasons.
My resources are limitedAnd my business-process can take too long. Say, the state denoted as “Don’t know” on the same pic at some step could take indefinite amount of time. That’s why I handle all my steps with separate process (in case of PHP) and I don’t use local Observer pattern. So quite popular approach described by Jimmy Bogard simply doesn’t work in this case.
Where to resume from in case of failure?Say, there was a database failure or some crucial http-request outage at some step. What step should my logic resume from? From the start? What a waste of time! I want to resume from as close as possible to the failure.
By the way, it’s pretty well-known rule of thumb in DDD that no more than one aggregate should be mutated within one transaction — take whether the Blue Book or the Red Book (Implementing Domain-driven Design). They don’t explain it though.
Closer look at event handling logic
Here are the steps that I implement when processing an event:
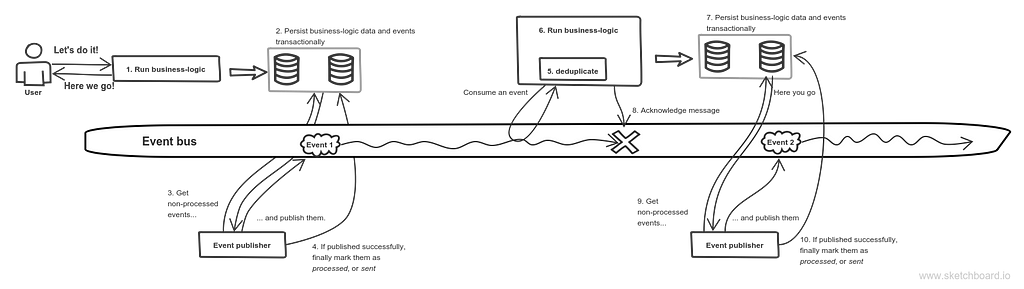 Basic event flow
Basic event flow
To fully depict what’s going on I start with the very beginning.Someone or something initiates a business-process. It could be a human, a script, a scheduler.
- Business-logic is run.
- Its outcome — both business-data and event resulted from business-logic— is transactionally persisted to the database. The event is not yet published, it’s just persisted.
- Some other thread or process regularly picks non-published events and publishes them.
- If published message was confirmed, that script marks them as sent or processed or published in a database, so that it won’t pick them again.
- The subscriber picks an event and checks if it has already been processed.
- If it hasn’t, then business-logic is run.
- The outcome is persisted — the same as step 2. But along with that, an event that was accepted by the current subscriber is persisted either — for deduplication check.
- The message removed from queue, or acknowledged, so it won’t be processed by this consumer again.
- Retrieve non-published events and publish them.
- If published successfully, mark them as processed.
If the process dies at steps 5–7, an event is still in the queue so it will be consumed again. If message broker or a message bus dies during step 8, the business-logic won’t be run again because of deduplication. If TCP connection or message broker dies at step 9, publishing would not be confirmed. This results in an event being left intact in the database, i.e. still marked as non-processed. If the process dies at step 10, retrieved message will be sent twice, which is not a problem since you have a deduplication logic.
Oh, and if you’re using Apache Kafka, which supports exactly-once semantics, then you won’t need a deduplication logic.
How to scale for high availability
Consumers scalingSay, I have one logical consumer, but there are more than one physical machines. But I want every message to be processed only once. Here is how this can be illustrated:
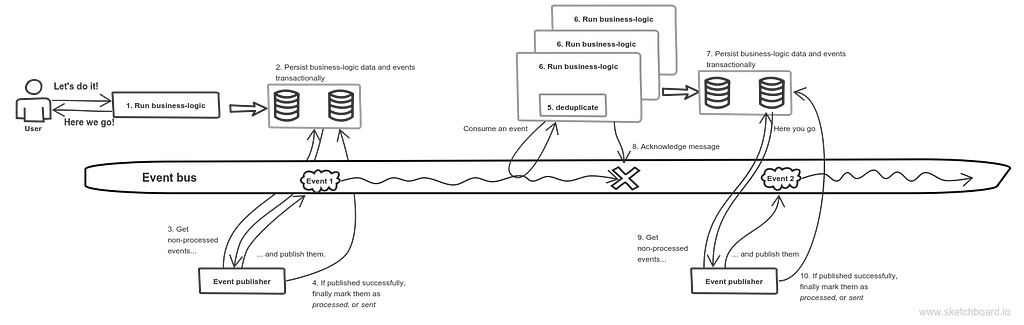 Scaling consumers number
Scaling consumers number
Enterprise integration patterns already have a solution. It implies utilizing a point-to-point channel. RabbitMQ has a direct exchange for that. It’s ok if message has command semantics. But what if it’s an event? It implies using Publish-Subscribe channel, or, in terms of RabbitMQ, fanout exchange. How do I have multiple physical consumers of the single logical service in this case? It can be achieved if an event would be published in fanout exchange, and there would be a single endpoint corresponding to a single logical service. This endpoint would receive an event and would publish it to a direct exchange with multiple competing consumers:
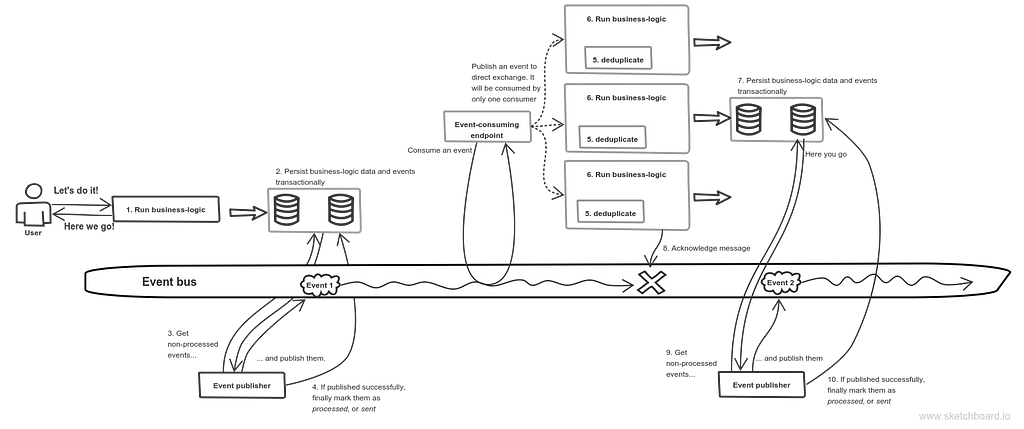 Competing consumers in event-driven architecture
Competing consumers in event-driven architecture
Broker scalingThe second point is about broker scaling. In RabbitMQ it’s implemented with clustering, which yet doesn’t replicate queues. Hence you’ll need to set up queue mirroring. In order to do so I need to put some load-balancing tool like HAProxy. But there is a caveat though. Say, you have three replicated RabbitMQ nodes. You created a queue on node #1. So it is a master queue. Hence it’s replicated across all nodes. But here is a kicker: when a consumer connects to node, say, #3, rabbit will internally routes this request to the node where that concrete queue was created.
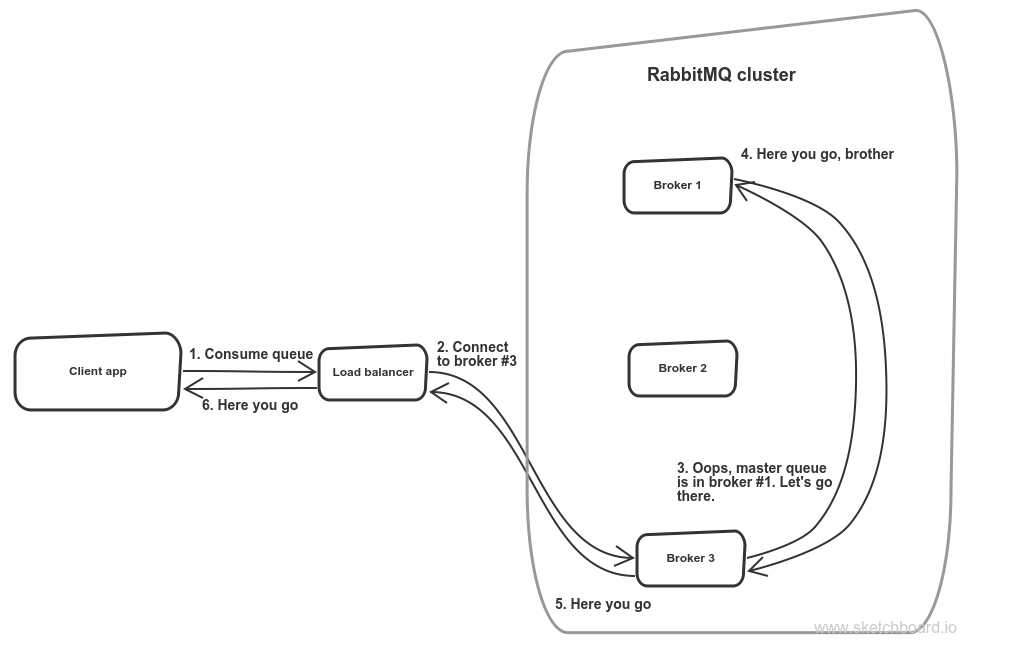 Highly available, but chatty queue replication scheme
Highly available, but chatty queue replication scheme
So this mechanism works well for failover, but it turns out to be too chatty during normal work.
To fix this problem I’m aware of two options. The first thing that came to my mind was to create three different queues on each node, so that each node has its master queue and two replicated queues. Then I wanted to have some hook that merges each replicated queue’s contents into a master branch. Well, sounds good by too complicated.
So the second option is just a kinda monitoring service that looks at rabbit nodes, which nodes are up and running, which are dead, where is a master queue, etc. Apparently, new queues should be created with this service.
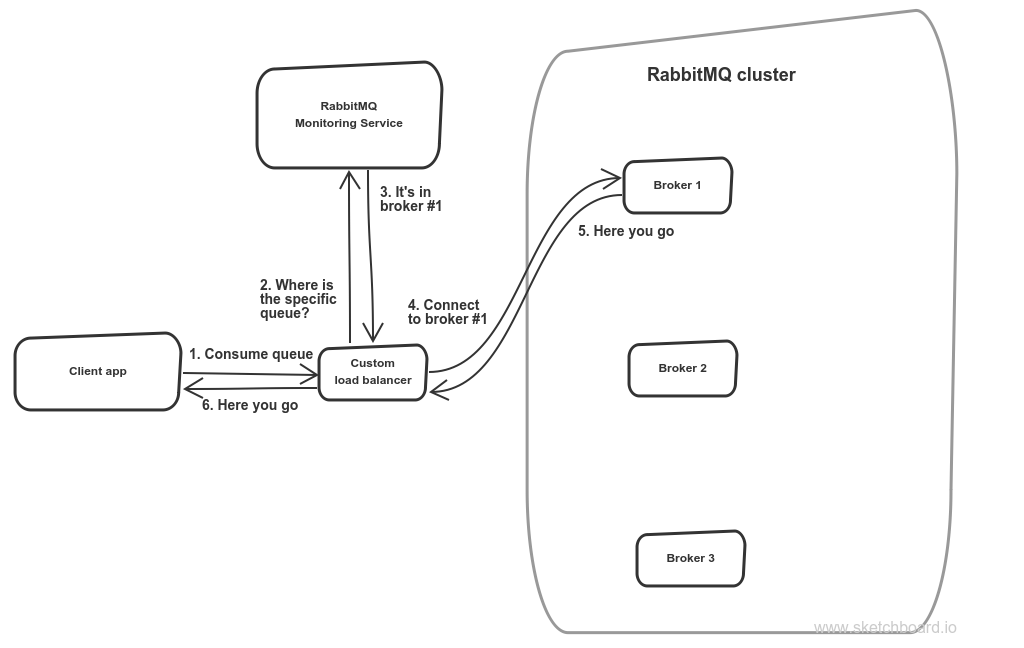 Tailor-made RabbitMQ monitoring service
Tailor-made RabbitMQ monitoring service
So this service provides a custom load balancer with an information which node to connect, so that my application code doesn’t need to mess with rabbit configuration.
But in case of brain-split situation, i.e., network partition within a RabbitMQ cluster, well, we’re in trouble. Some messages more probably than not will be discarded, and some of them manually (and painfully) merged.
Tips for high performance
Shovel pluginSay you don’t want your service to share any infrastructure, for whatever reason. Probably you have your bus highly loaded and you want to move some load to another bus, probably you don’t want your resources shared between services. Whatever, in RabbitMQ there is a Shovel plugin that can acts as client that moves messages from one broker to another. That’s how it could be illustrated:
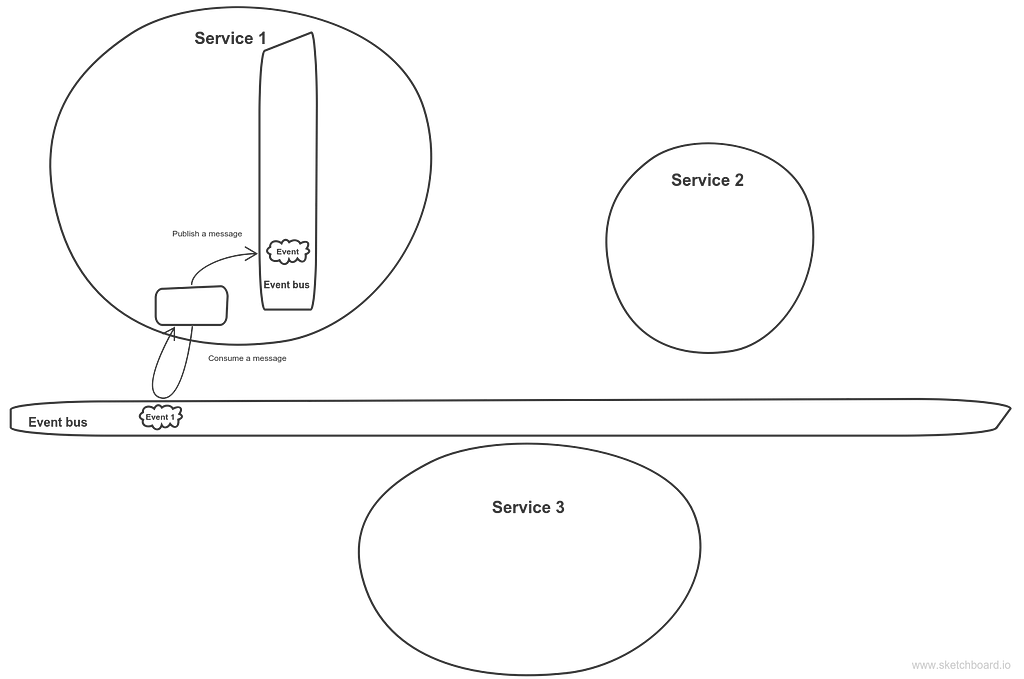 Shovel plugin in action
Shovel plugin in action
Use prefetch_countDon’t make rabbit push new message into channel as it arrives — and don’t overload the channel. Consumer’s resource are not endless. Use a prefetch_count setting:
The value defines the max number of unacknowledged deliveries that are permitted on a channel. Once the number reaches the configured count, RabbitMQ will stop delivering more messages on the channel unless at least one of the outstanding ones is acknowledged.
Be aware that by default the buffer is unlimited!
The maximum amount that prefetch_count should take is apparently the maximum number of processes (in terms of PHP) or threads (Java) allowed by a consumer. Don’t set it too low. If it is set to 1, your consumer will process only one message at a time, regardless of how much resources are deployed. Of course, sometimes it could make sense. Here are some other strategies depending on consumer’s nature.
It will help you to utilize a fair dispatch with concurrent consumers as well. Say, you have two consumers, that can handle two kind of messages. The first message handling takes almost no time, while the second is really very heavy. So it might turn out so that all the lightweight messages are round-robined to one consumer, while all the heavy messages to the second. So the heavy messages start to pile since they are pushed to a channel as soon as they arrive in a queue. So prefetch_count prevents this situation.
Empty queue is a fast queueMake sure your queues are not overwhelmed. RabbitMQ’s queues are fastest when they’re empty.
What to do if a new service pops up after the system is up and running?
Since all my messages are persisted, I just force them to publish. Deduplication logic will work out on every endpoint, and a new service will consume everything it’s interested in.
But things can be more complicated. There could be a complex logic in message ordering. So another approach is to simply retrieve all data that a new service is interested in and insert it in new service’s database.
Message ordering
There are always some limitations on message ordering capability. For example, in RabbitMQ message ordering is supported only within a specific queue and a single consumer:
AMQP 0–9–1 core specification explains the conditions under which ordering is guaranteed: messages published in one channel, passing through one exchange and one queue and one outgoing channel will be received in the same order that they were sent.
Similarly, Kafka maintains ordering within a partition:
Kafka only provides a total order over records within a partition, not between different partitions in a topic.
In case I’m using event-driven approach with sagas (or, in terms of Enterprise Integration Patterns, a Process manager), the subscriber that consumes an event, i.e., saga, is aware of semantics of every event. So the sagas can (and should) be implemented so that there is no ordering at all. It means that they should not put restrictions on message ordering. Take for example my e-commerce example. Let’s assume that order saga is created after an order was actually placed by a user — hence, with an event OrderPlaced. Let’s also assume that after a user placed his order he payed it. So an event OrderPayed was published. If it was published after an OrderPlaced event, it by no means indicates that it will be consumed in the same order. So my saga implementation should be ready to this. For example, saga should have the ability to be created with both events, checking if it already exists either. This implies that events should be self-contained, but without too much data. Remember, events are used for some important notifications, not for passing data.
In closing
I’m a big fan of event-driven approach. If you tried it — it would be great to hear about your experience with it.

Event-Driven Architecture Implementation was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.