Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
The Exploration-Exploitation Dilemma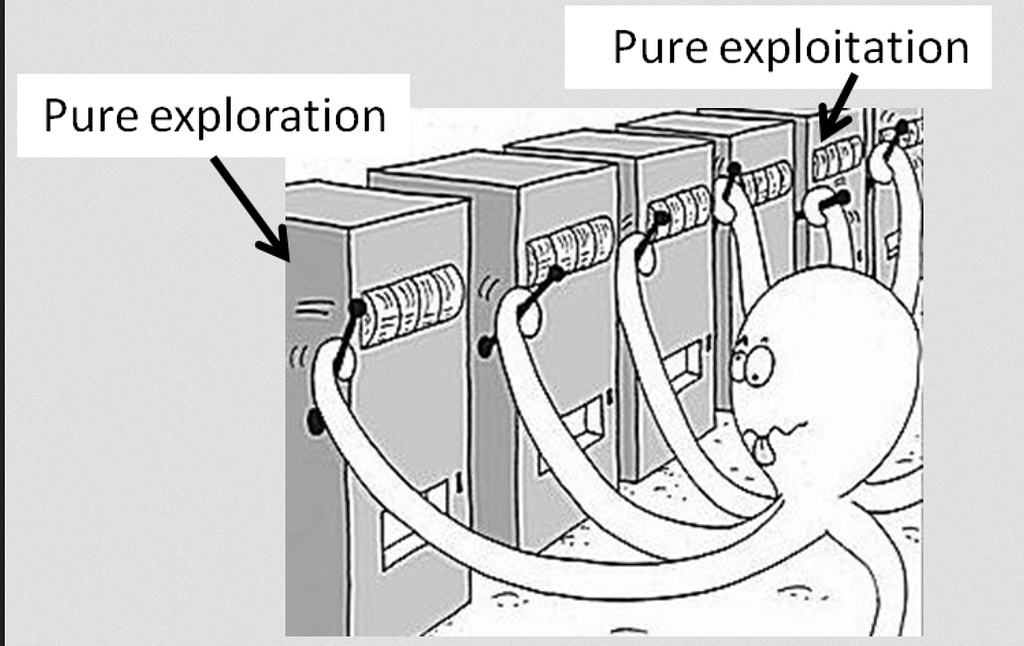 Muti-Armed bandit [Explore Vs Exploit] — Source
Muti-Armed bandit [Explore Vs Exploit] — Source
Muti-Armed bandit [Explore Vs Exploit] — Source
If you have not read Part 1of this series, please check it out here.
In a learning process that is of trial and error type, an agent that is afraid of making mistakes can be problematic to us.
Exploitation is about using what you know, whereas Exploration is about gathering more data/information so that you can learn.
Learning to balance explore vs exploit is extremely important in order to learn a successful policy.
Examples
- Let’s say there is a dog in a maze and you have to train a agent that controls the dogs action. There are 3 possible types of rewards, dog getting to bucket of water gets him +1 points, dog getting to poisonous food gets -10 points and dog getting a bone gets +100 points. Optimal policy here would be to get the dog away from poison and head him towards the bone. Let’s say we let our agent to play the dog for 5 episodes. In the first one, dog takes a left turn from certain position in the world and gets to poison receiving -10 as reward points. In the next one it avoids taking left turn instead takes a right turn, where he gets to water receiving +1 as reward points. Now, agent will try to exploit the learned path that gave +1 point because for him going right is a better policy based on first two episodes. Our dog, our model, will be stuck in a policy of local maximum where he is sacrificing for a moderate reward.
2. Multi-Arm Bandit: Slot machines are called bandits because they’re taking your money. Suppose, you go to a casino and you have a choice between 3 slot machines. Each slot machine can give you a reward of 0 or 1 (trivializing). Your goal will be obvious to maximize your winning chances. Since, you don’t know the win rate of each slot machine, so you will have to play/explore each of them significant times to have get an idea of which machine has higher win rate. Once, you get that higher reward machine then you can exploit it. But, you will have to spend lots of time playing suboptimal bandit arms. Earlier people used to solve this problem by A/B testing but it had it’s dis-advantages like you have to predetermine ahead of time the number of times you need to play each of the bandit to get statistical significance. It also doesn’t allow to stop the tests early even if you have calculated 90% success rate for bandit 1 after certain episodes.
Both of the above examples showed the sheer necessity of technique that can solve this dilemma. In the next blog, we will be talking about the same.
If you have not read Part 3 of this series, please check it out here.

Reinforcement Learning — Part 2 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.