Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Is Object Detection a Done Deal Yet?
A few years back it was widely known that Object Detection was a hard problem to solve. The comic below was just a few years back. Things have changed in this short time quite drastically.

And with the advent of Deep Neural Network Architecture -Convolutional Neural Network (CNN) in particular, as well as the development of the CUDA library that started to use the multicore characteristic of the gaming/rendering GPU’s and the open collaborative research and open source implementations in this field,things have changed drastically for the better. and not only would it be possible to recognize if it is a bird, but which bird as well. Here is a snapshot from Google Cloud API Demo link — https://cloud.google.com/vision/docs/drag-and-drop
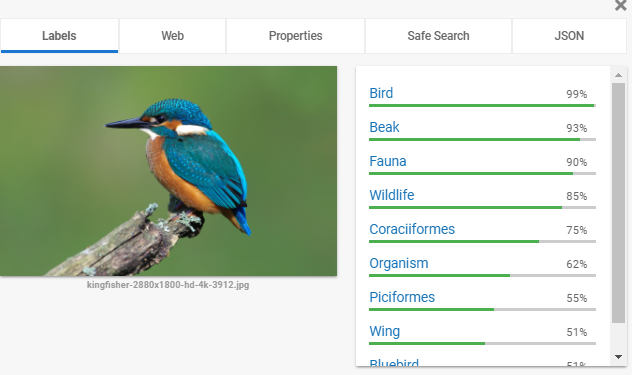
(If you did not know (I did not know this) -The Coraciiformes are a group of usually colorful birds including the kingfishers, the bee-eaters, the rollers, the motmots, and the todies — https://en.wikipedia.org/wiki/Coraciiformes)
Things that would have taken a 15-year research team to do are now rapidly becoming reality. Soon or already machines will be able to detect maybe better than what you can detect. But there are caveats here.
Why am I writing this?
I am not a researcher but have been basically using open source algorithms and frameworks for Object detection for about two years now. Started from the ML-based HOG and HAAR in OpenCV, then the faster version of that via CUDA and GPU and finally since tuning the parameters of these systems to works across different videos was proving to be futile, went ahead with the neural network based method; I wanted to write this as there is a tendency by many who have used the opensource implementations like Yolo, to think that it is a done done; also heavy marketing by a lot of small and specialised companies, who follow similar thinking, and promising visual automation, either customisable or customised for some vertical. (does it remind of IBM Watson marketing).
Maybe when we humans see a system is able to detect and/or classify some images perfectly, we have a tendency to imagine and extend the capability to all scenarios; because we, humans, are great in generalizing; and with CNN we have something similar, better in generalizing features, but nowhere great yet. Read on.
The State of the Art.
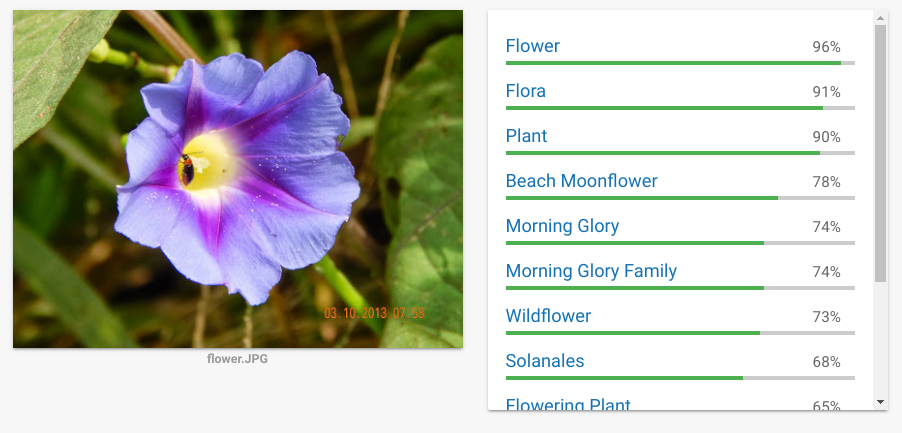
Here is a result from a photo I took long back; I used the Google Cloud Vision API Demo page to upload and check. I choose Google API because they are the best in this/ or one of the best.
Wow! Morning Glory Family! This is some information! I am really impressed. Anyone would be. Same like IBM Watson beating the human contenders in Jeopardy, or the Go playing AlphaMind from Google DeepMind.
Our expectation increases exponentially. We tend to equate the system with human-like abilities for vision, with computer-like fastness and correlation to digitized information. The perfect marriage. Imagine what a trained network can do in medical scans. Every vision related problem seems to be generalized as a possibility and then automated and augmented with information to create a system. This is partly true, but there are gaps, large gaps, not unbridgeable, but which requires work. Let us see a few.
Note that in the technical architecture of CNN there is more complexity in object detection than object classification. Image classifiers have very high accuracy in test’s compared to detectors (they need to also detect the position of the object and draw a bounding box on the image).
A system that can classify a flower into its family would surely be able to decipher the details from the below photo?
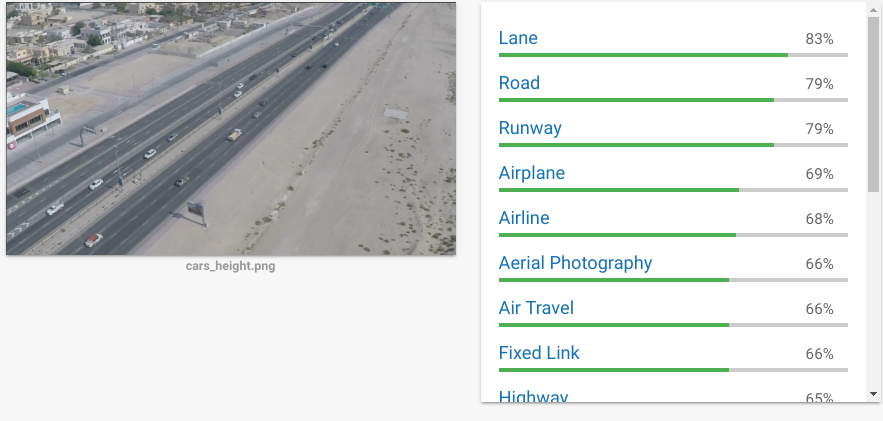
However, not a single Car is ‘detected’ (technically this is a classifier). Let us give another clearer shot to the system.
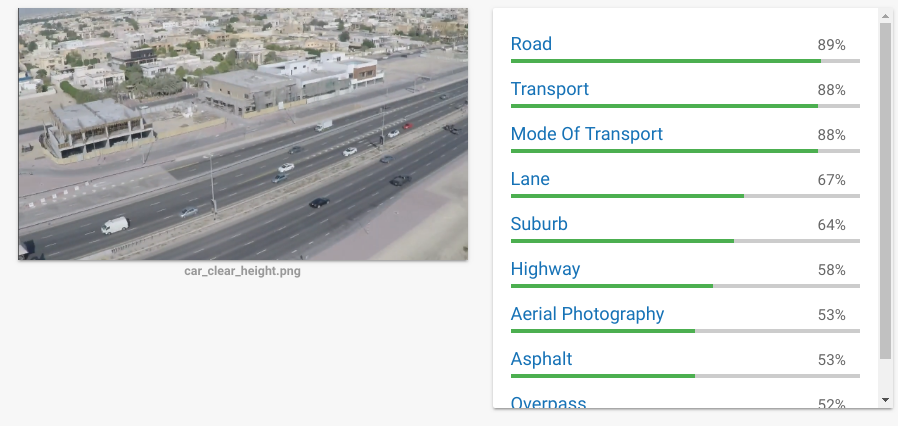
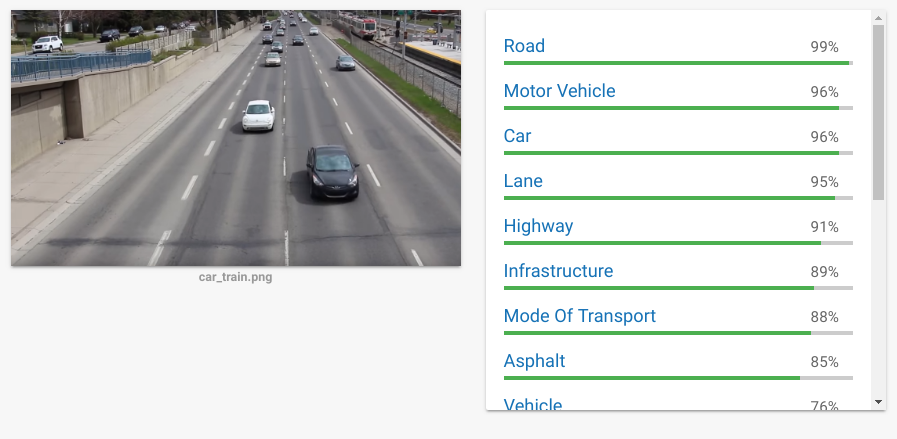
Still no Car detected.Let us make the car/cars slightly bigger (right image) ;and now it is detecting cars with 96% confidence. Why is that ?
Scale Invariance
Let us make the car a lot bigger
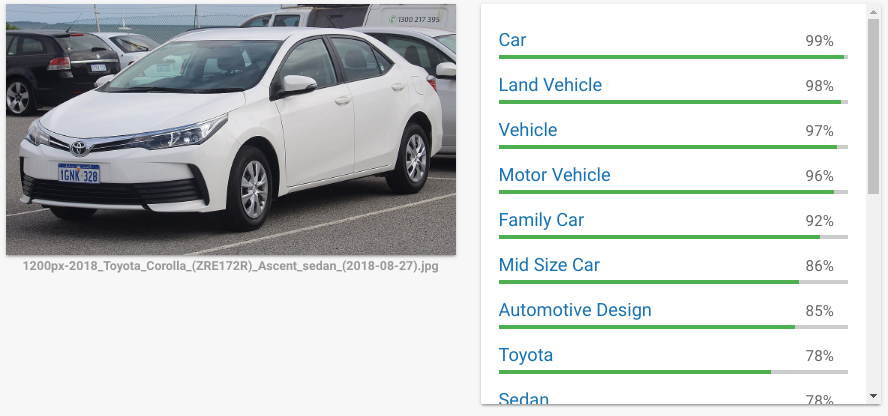

It actually detects it is a Toyota Corolla with 52% chance and that it a car and that it is a Toyota with high confidence.
Rotation Invariance
CNNs (or the current CNN networks) are not rotation invariant, it has to be trained for that (data augmentation).Let us do a small change ; I invert the above car picture and try.
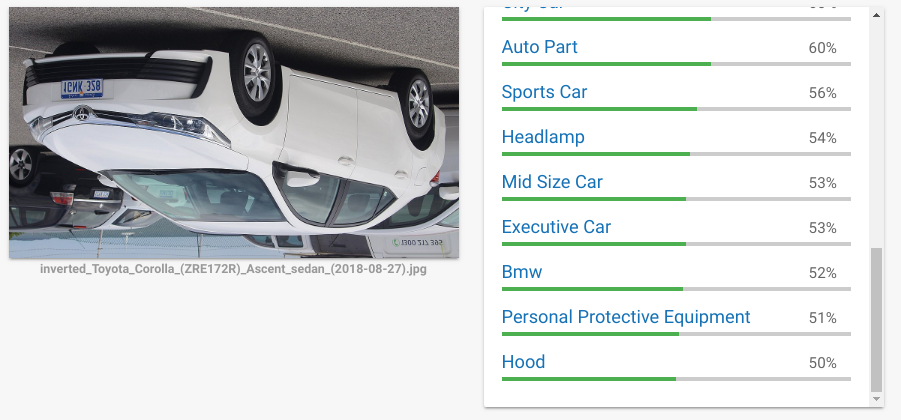

It is detecting as a Car with high accuracy; no problem with that; Toyota seem’s to have vanished to Bmw and I rotate it still 90 degrees and then it looses the Bmw confidence too, but Wheels and other parts are gaining.
This will be more evident with images that are less common. Here is an image of a tap rotated 90 degrees and you could see the confidence changing (Chair ?)
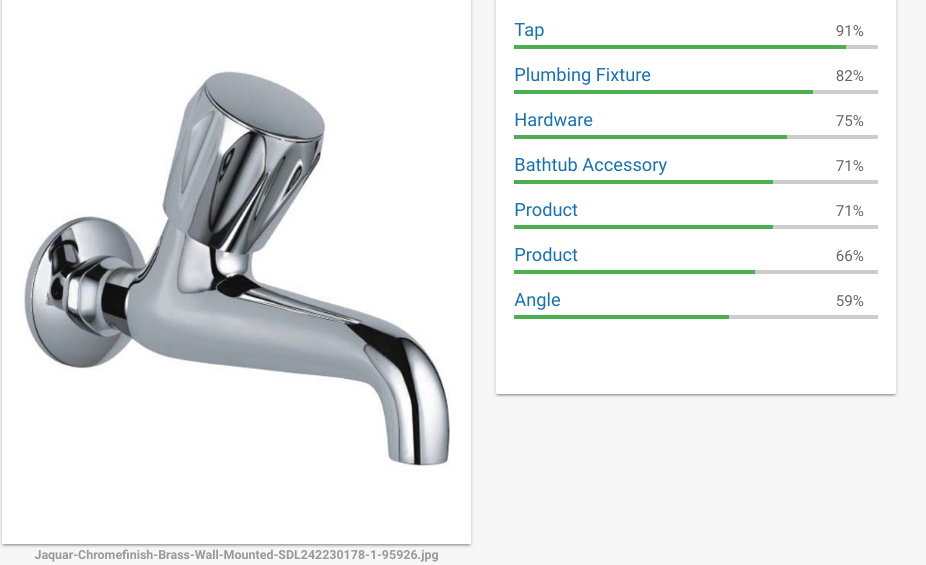
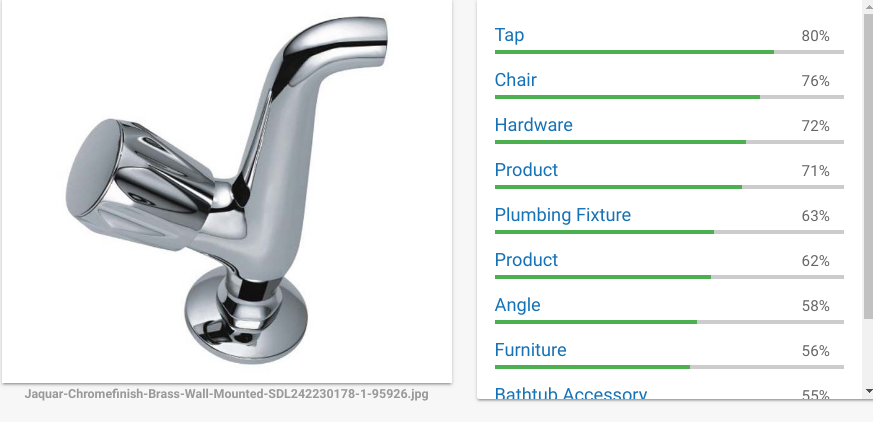
During training, each image is usually augmented via transformations to avoid these sort of errors, minimize translation invariance.
But as you can see when the angle changes from the training set, due to camera angle or taking random pictures from the wild, the output changes too. I have just used random images; my aim here is not to show how bad the system is and confuse the system with difficult images; but to point out certain aspects.
This may seem surprising to many. CNN’s are supposed to be scale invariant and translation and rotation invariant. Or is that just loose trade talk. Going slightly technical, let’s dig further -don’t worry I won’t go more technical than what can be Googled and followed; as basically I am also at that same level here.
There is a general conception that Pooling (Max Pooling) provides scale and translation invariance. This is both true and false. What needs to be understood that pooling helps in ‘learning’ invariance, and for learning the NW should be trained with images. Also CNN’s are invariant to translation. I guess there are few who think,mean rotation also same, as a translation. But translation here means shifting the position of the object left, right , up or down. (shown here clearly)
Maxpooling helps here. This answer , illustrates this lucidly. Here no data augmentation is needed. Assuming that a CNN is good in detecting a picture of a cat, it will detect a cat translated anywhere in the frame.
Here is from a very reputed source the Deep Learning book by Ian Goodfellow and Yoshua Bengio and Aaron Courvill. Along with Geoffrey Hinton and Yann Lecun, Bengio is considered one of the three people most responsible for the advancement of deep learning during the 1990s and 2000s”
In all cases, pooling helps to make the representation approximately invariant to small translations of the input. Invariance to translation means that if we translate the input by a small amount, the values of most of the pooled outputs do not change — Deep Learning book , http://www.deeplearningbook.org/
But regarding scale invariance and rotation invariance; here is from the same book
Convolution is not naturally equivariant to some other transformations, such as changes in the scale or rotation of an image.
And there are other papers that have tested current networks and reported the same. Here is a quote from a Dec 2017 paper (2)
“We obtain the surprising result that architectural choices such as the number of pooling layers and the convolution filter size have only a secondary effect on the translation invariance of a network. Our analysis identifies training data augmentation as the most important factor in obtaining translation-invariant representations of images using convolutional neural networks.” From “Quantifying Translation-Invariance in Convolutional Neural Networks (Eric Kauderer-Abrams Stanford University) “
And from another recent paper May 2018
Deep convolutional neural networks (CNNs) have revolutionized computer vision. Perhaps the most dramatic success is in the area of object recognition, where performance is now described as “superhuman” [20]. …
Despite the excellent performance of CNNs on object recognition, the vulnerability to adversarial attacks suggests that superficial changes can result in highly non-human shifts in prediction …
Obviously, not any data augmentation is sufficient for the networks to learn invariances. To understand the failure of data augmentation, it is again instructive to consider the subsampling factor. Since in modern networks the subsampling factor is approximately 45, then for a system to learn complete invariance to translation only, it would need to see 452 = 2025 augmented versions of each training example. If we also add invariance to rotations and scalings, the number grows exponentially with the number of irrelevant transformations
From Why do deep convolutional networks generalize so poorly to small image transformations? Yair Weiss, Aharon Azulay ELSC Hebrew University of Jerusalem https://arxiv.org/pdf/1805.12177.pdf
If that is the case, how do the Google API been able to recognizance the inverted and rotated car in the tests that we showed earlier ?(notice that it got the Car pretty high, and only missed on the other details like brand, which it may have not trained that strong).
Data Augmentation
The key is data augmentation. Basically the input image is used along with rotations, scaling, noise etc generated from the image as other images to the training. Some good explanation is here https://medium.com/ymedialabs-innovation/data-augmentation-techniques-in-cnn-using-tensorflow-371ae43d5be9.
CNN’s are scale invariant to some level, if it is trained to be; as pooling implementation will then be able to handle that. Also rotational invariance has to be trained in.
‘Learning’ Invariance to Rotation via Pooling
Let us see rotational invariance first , how a CNN can be trained for that first as it is bit easier. Here is the illustration from the Deep Learning book.
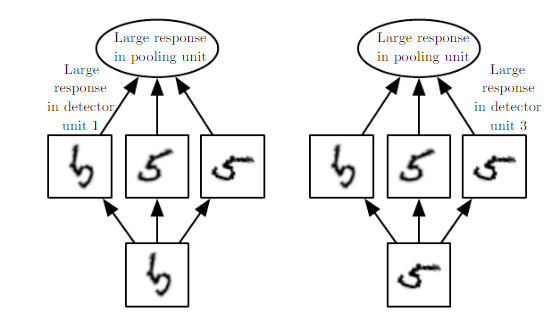 source pg 338 http://www.deeplearningbook.org/contents/convnets.html
source pg 338 http://www.deeplearningbook.org/contents/convnets.html
Example of learned invariances. A pooling unit that pools over multiple features that are learned with separate parameters can learn to be invariant to transformations of the input. Here we show how a set of three learned filters and a max pooling unit can learn to become invariant to rotation. All three filters are intended to detect a hand written 5.Each filter attempts to match a slightly different orientation of the 5. When a 5 appears in the input, the corresponding filter will match it and cause a large activation in a detector unit. The max pooling unit then has a large activation regardless of which detector unit was activated…
pg 338 http://www.deeplearningbook.org/contents/convnets.html
Basically we need to either augment the training images by rotating , or get a data pool of images which are taken at different angles and use them for training the CNN.
Invariance to Scale (Size of the Object)
This is a little more complex. For real time detection we use a CNN called a Single Shot Detector. Single shot detectors sacrifice some accuracy for performance.
Here is one picture you may have seen from the YOLO home page.
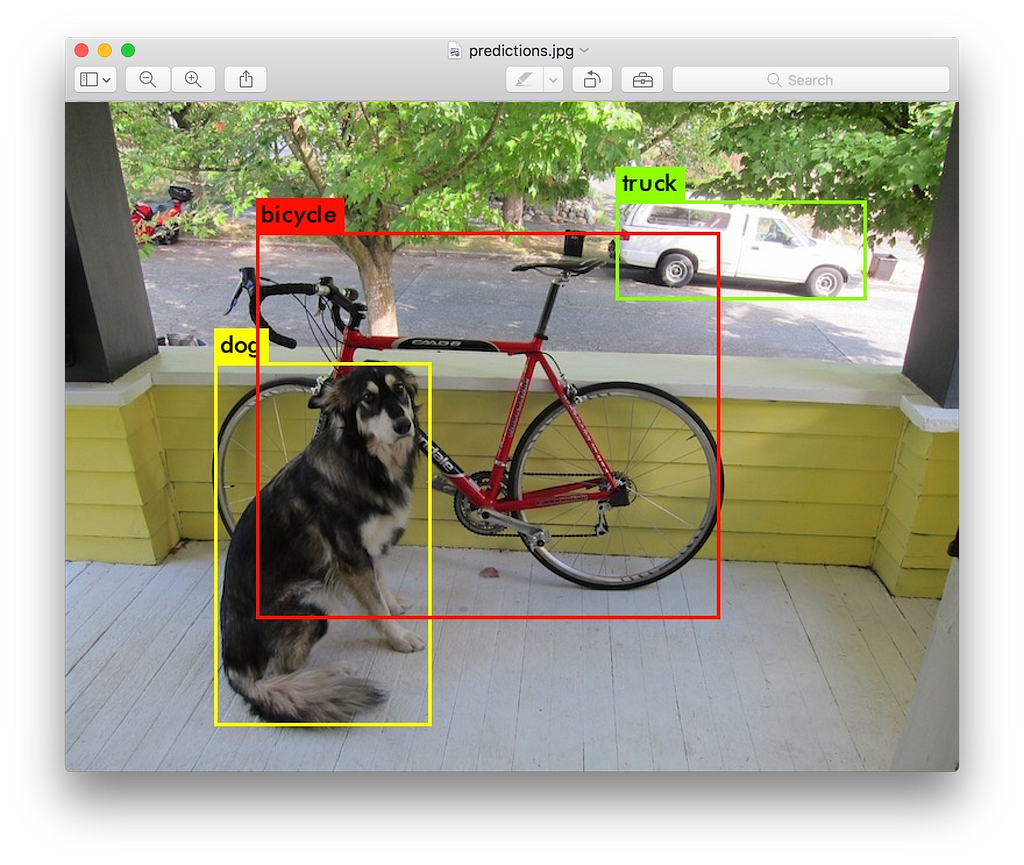 from https://pjreddie.com/darknet/yolo/
from https://pjreddie.com/darknet/yolo/
Multi object detection . Note- Detection is different or more difficult from classification in that it needs to also predict the bounding boxes that the object is present in.
Here is the output on a previous version of Yolo (Yolo v2, the current v3 seems to have improved a lot) on a pictures taken at a height.
 Yolo v2 from an arieal picture- Image resolution problem
Yolo v2 from an arieal picture- Image resolution problem
And if you think these type of pictures or use cases are rare, I beg to differ. Many industry use cases are similar to this; or from some high lamp pole. The friendly cat and dog on a porch type of pictures are rare.
Most of the things that work very well in a demo is useless in production or for a particular customers use case; and one reason what has prompted me to write this.
As I said why the NW does not detect small sizes though trained well for large can be due to two reasons.
Problem 1 :Limit of Input resolution /Scaling down of Images
Here in YoloV2 it scales images down; the input image was a frame from a HD video feed. Scaling it from input (1280*720) down to (416*416) immediately destroys lot of features, esp of small objects. This is the first problem. Lesson use a NW and implementation that will take higher resolution images (Retinanet), plus have a decent GPU with enough memory (GTX 1080 should do)
If we cut the above frame into 4 frames and give it to Yolo v2 individually and then stitch together, it performs well (a good solution at that time by one of my team mate). There is a cost involved here; one of speed; and then the complexity overhead of removing overlapping boundary boxes; as a straight slicing may cut the objects itself in the boundaries; so logic of overlapped cutting and then ignoring possible duplicates has to be done.
 obfuscated image for demo
obfuscated image for demo
Problem 2: CNN layers removes feature; not good news for small object detection with deep neural networks.
This is a bigger problem. Each convolution layer basically looks for some patterns while loosing some details; so at some depth, all these small cars features completely vanish.
SSD uses layers already deep down into the convolutional network to detect objects. If we redraw the diagram closer to scale, we should realize the spatial resolution has dropped significantly and may already miss the opportunity in locating small objects that are too hard to detect in low resolution. If such problem exists, we need to increase the resolution of the input image.
What do we learn from single shot object detectors (SSD, YOLOv3), FPN & Focal loss (RetinaNet)?
Here is a little more technical explanation from a recent published paper
Since feature maps of layers closer to the input are of higher resolution and often contain complementary information (wrt. conv5), these featuresare either combined with shallower layers (like conv4, conv3) [23, 31, 1, 31] or independent predictions are made at layers of different resolutions [36, 27, 3]. Methods like SDP [36], SSH [29] or MS-CNN [3], which make independent predictions at different layers, also ensure that smaller objects are trained on higher resolution layers (like conv3) while larger objects are trained on lower resolution layers (like conv5).
An Analysis of Scale Invariance in Object Detection — SNIPBharat Singh Larry S. Davis University of Maryland, College Park
http://openaccess.thecvf.com/content_cvpr_2018/papers/Singh_An_Analysis_of_CVPR_2018_paper.pdf
Excellent blogs from Jonathan Hui ; he explains here how Yolo v3 overcomes this problem with Feature Pyramid; so this may not be too much of a problem now, also other NW like Retina net perform well as well. But for quite a lot of time it was a surprise which took some time for us to understand and find a way out. Shows how on the initial stages the industry and research is now.
Here is from another paper April 2018
We provide an illustration of the motivation of the paper …. Pedestrian instances in the automotive images (e.g., Caltech dataset [11]) often have very small sizes….. Accurately localizing these small-size pedestrian instances is quite challenging due to the following difficulties. Firstly, most of the small-size instances appear with blurred boundaries and obscure appearance. It is difficult to distinguish them from the background clutters and other overlapped instances. Secondly, the large-size pedestrian instances typically exhibit dramatically different visual characteristics from the small-size ones
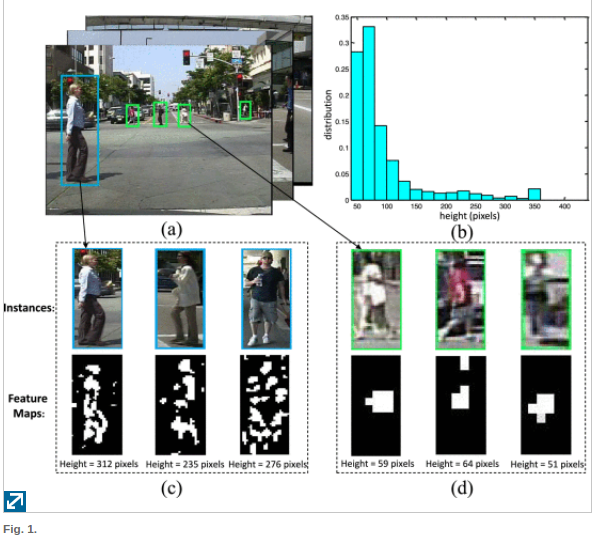 source https://ieeexplore.ieee.org/abstract/document/8060595
source https://ieeexplore.ieee.org/abstract/document/8060595
For instance, body skeletons of the large-size instances can provide rich information for pedestrian detection while skeletons of the small-size instances cannot be recognized so easily. Such differences can also be verified by comparing the generated feature maps for large-size and small-size pedestrians, as shown in Fig. 1.
From Scale-Aware Fast R-CNN for Pedestrian Detection By Jianan Li ; Xiaodan Liang ; Shengmei Shen ; Tingfa Xu ; Jiashi Feng ; Shuicheng Yan
Scale Invariance- Training it in
From my experience, the CNN’s currently are not scale invariant. It may be do to the above two factors, feature loss when the image is small ,compounded with the features loss in deep neural network. However we have found that if we are able to prepare a training data set that have both small and large objects the current network is able to detect different scales with the same class as long as it can work on input images without scaling down much.So training the network has become sort of a skill now.
Finally — the Elephant in the room ; Need for large good quality human annotated image set for Training
Here is the most painful things about CNN’s today. You need thousands to literally hundred thousands of good annotated images of an object for a good training; that is good enough generalization without over-fitting.
The presence of COCO image set is for image detection, what ImageNet is for image classification.
However there is a high chance that the object you want to detect is not one of the 80 classes of images in COCO.
Why is this so important ? For this we need to understand a bit about generalization.
The central challenge in machine learning is that our algorithm must perform well on new, previously unseen inputs — not just those on which our model was trained. The ability to perform well on previously unobserved inputs is called generalization Chapter 5.2 Deep Learning book
When a neural net trains, it uses the divergence from the test data to learn the correct weights via back propagation. If there are only few images to train on, the NW will learn too well (or be too specific) to the training data, and will perform worse on data in the wild. To reduce there there are techniques used. Instead of just train and test, there is also a third set of images called validation set, and if the results starts to diverge too much from validation set, though it matches the test set more, then it is an indication to do a ‘early stop’ of the training.
The other option is using drop-out.
Simply put, dropout refers to ignoring units (i.e. neurons) during the training phase of certain set of neurons which is chosen at random. By “ignoring”, I mean these units are not considered during a particular forward or backward pass. from https://medium.com/@amarbudhiraja/https-medium-com-amarbudhiraja-learning-less-to-learn-better-dropout-in-deep-machine-learning-74334da4bfc5
A lot of questions abound in the internet regarding how to prevent over-fittinghttps://github.com/keras-team/keras/issues/4325
Apart from the methods above, the base is to have enough data points to train with.
To prevent overfitting, the best solution is to use more training data. A model trained on more data will naturally generalize better. When that is no longer possible, the next best solution is to use techniques like regularization https://www.tensorflow.org/tutorials/keras/overfit_and_underfit
A word about Transfer Learning
In the recent Google NEXT event AutoML was presented.If using AutoML for Vision, it was claimed that ten to twenty images of leaves are all what is needed for training. I am not sure of the internals of AutoML, but my inference is that, it could be from transfer-learning (practically for a NW like Retinanet described here).
Here is the same sentiment from another source
The origin of the 1,000-image magic number comes from the original ImageNet classification challenge, where the dataset had 1,000 categories, each with a bit less than 1,000 images for each class (…. This was good enough to train the early generations of image classifiers like AlexNet, and so proves that around 1,000 images is enough.
Can you get away with less though? Anecdotally, based on my experience, you can in some cases but once you get into the low hundreds it seems to get trickier to train a model from scratch. The biggest exception is when you’re using transfer learning on an already-trained model. Because you’re using a network that has already seen a lot of images and learned to distinguish between the classes, you can usually teach it new classes in the same domain with as few as ten or twenty examples.From https://petewarden.com/2017/12/14/how-many-images-do-you-need-to-train-a-neural-network/
But if we have to detect for a object class of an image that is not in the same domain as other images on it is trained for, this transfer-learning will not work. To give a crude example — it is definitely possible to train a system to detect based on few images of say nails; but then it will see everything as nails- literally. Basically since CNN’s are very deep neural networks, they need a lot of data( read images) to generalize. This calls for lot of work in collecting the required images, and then annotating it; and then training the network in a way, and till such time as to get the optimal result,preventing underfitting or overfitting.
The Future
If you can see a glimpse of light, you can already start imaging the sky; I guess very soon we will be out of this tunnel going by research -CapsuleNet coming from stalwarts like Geoffrey Hinton.

Is Object Detection a Done Deal? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.