Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Learnings from getting my feet wet in a Kaggle competition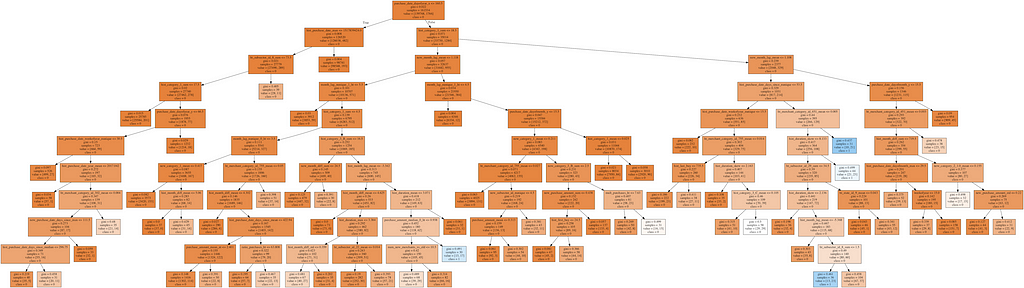 Protip: If you overfit enough, you will get great results on your training data
Protip: If you overfit enough, you will get great results on your training data
Protip: If you overfit enough, you will get great results on your training data
The dust settles on the first Kaggle competition I’ve put serious time into and though still quite far from the coveted top spots, I reached the goal I had set out of earning a first medal for my profile page, and even got a silver medal for placing in the top 2% in the competition, ending up as number 58 out of over 4000 competing teams.
More than the end placement though, the competition gave some good learnings when it comes to competitive data science, and data science in general, that I’m noting down in hope it will help other people avoid making the same mistakes I’ve made. Learning from others mistakes is the best strategy after all, since you won’t have time to make them all yourself.
1. You are not special. You’re not a beautiful and unique snowflake
Start simple, get inspiration from kernels available and read through the competitions discussion forum. The likelihood that you will have a genius break-through idea early on that no one else have thought of is very small.
What not to do as first steps includes;
- Taking inspiration from the Prod2Vec paper and try word2vec embeddings or various categoricals as the first thing after the first simple feature aggregations.
- Seeing how that didn’t work, spend a lot of time on t-SNE dimensionality reduction of the same categoricals, not even if you are using an autoencoder trained on the non-outlier set.
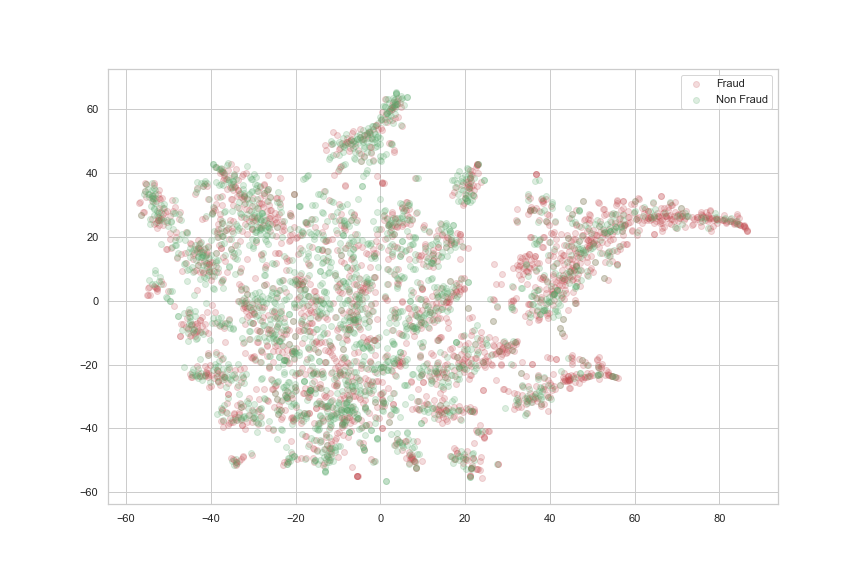 This 50/50 sample of outliers and non-outliers might look promising, but the extreme imbalance of the dataset adds too much noice for it to yield anything useful in the end
This 50/50 sample of outliers and non-outliers might look promising, but the extreme imbalance of the dataset adds too much noice for it to yield anything useful in the end
- Field-aware Factorisation Machines. Definitely interesting to try out, and read through the paper, but it was a poor fit trying to try to shoe horn it into this problem.
- Rolling window time series features. Trying to catch temporal aspects of customer behaviour changes over time. I still like the idea though it didn’t pan out on this data set and it was a rabbit hole I went way too deep into before I explored some much simpler feature engineering ideas.
That said though, this amount of failed experiments have meant a lot of good learnings for the future. I might sum up the whole experience in Thomas Edisons immortal words:
I have not failed. I’ve just found 10,000 ways that won’t work.
Rather than what not to do, let’s move on to what is a better way to spend your time.
2. Get to know your data
I know, I know. This is so elementary that it feels silly to bring up. Still, it’s so easy to proceed to model building after just a cursory data exploration, and in case the data contains some curveballs, you will end up spending a lot of time on a hopeless cause.
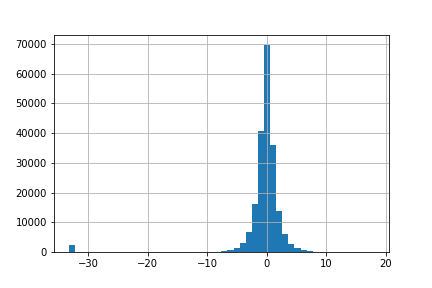 Distribution of target variable. Is this a regression or classification task?
Distribution of target variable. Is this a regression or classification task?
Make sure to read through the data descriptions, write down the question marks you have and try to answer them.
In hip ML circles, everyone these days wants to brand themselves a data scientist and not a data analyst. Still, I’d say a thorough understanding of your data in most cases is worth much more than any fancy algorithms you might throw at it.
3. The struggle (with data leakage) is real
You have this brilliant idea, calculate outliers likelihood per merchant and use it as feature in your regression model. You see amazing results in your train and val sets, and horrifying atrocities on the test set. What happened?
Stacking models is powerful, maybe not so often for production use cases but definitely to squeeze out the last third decimal loss reduction in a Kaggle competition. If you are not disciplined and careful though, you end up shooting yourself in the foot. Make sure you read up on data leakage and model stacking before you go wild.
4. Deep Learning won’t automagically solve all your problems
Though deep learning is sometimes hyped as the end-all solution, there are still plenty of problems where other algorithms perform better in practice.
With this datasets combination of regression and classification aspects, gradient boosted tree models turned out clearly ahead of neural networks that had a hard time converging on a stable minima due to the non-continuous distribution of target variables.
Tree based models further have the great benefit of not being based on the same assumptions of normality as many other models, meaning you don’t have to do as much data preparation. Starting with a Random Forest and/or Gradient Boosting Machine will give you a good benchmark to beat if you decide to get fancy with neural networks.
Seriously, it’s quite insane how good LightGBM is.
5. Speed of iteration over correctness
With big datasets and number of features, everything slows down. The speed of a full training iteration is equal to how fast you can run an experiment too validate if you are on the right track or wasting your time, so this is a big problem. Thus you should always be on the look-out for how to eliminate redundant work.
A first step is to store aggregated features so you don’t have to recreate them every training run if nothing has changed, and so you easily can mix and match different feature combinations during different tests.
Further, for many intents and purposes, working on subsets of data is good enough and much faster. When possible, work with smaller samples during analysis to evaluate ideas and trust in the law of large numbers that the sample is somewhat representative.
An apt metaphor for the efficiency of speed of iterations over absolute correctness would be how mini-batch gradient descent allows faster convergence than using the full data for each learning iteration.
6. …and all the pieces matter
Going rogue in a Jupyter notebook only works for so long before the freedom given by the interactive programming paradigm ends up with your cell execution in the wrong order, or you realise you’ve accidentally changed the code used to generate the feature set that got you those splendid results and now you can’t figure out how to recreate them. It’s true what they say, with great power comes great responsibility, and the two things that has helped me get a better structure during work are:
- Make sure you store relevant hyper parameter settings and feature combinations used for each experiment together with the cross validation results.
- Use version control to be able to go back to earlier states when you encounter dead ends.
My current workflow; import local package containing the stable code and use automatic reload in the notebook so that changes in the files are automatically detected and picked up. Jupyter magic;
%load_ext autoreload%autoreload 2
Once this works, you can prototype new logic and functions in the notebook while calling all stable logic from your package. When you find a new piece of logic that is worth saving, directly move it over to your package, ensure nothing got lost in translation and then commit. If related to an experiment, you can store the current CrossVal in the commit message.
Conclusion or: How I Learned to Stop Worrying and Love the Bomb
After the competition ended, the public leaderboard vs. the private leaderboard became a great shake-up, and I was at first very positively surprised to see that I had overnight advanced quite a bit.
When checking the submissions though, I fell like the ground disappeared underneath me when I realised that my final two candidate submissions that I was ranked on were in fact not my best submissions. Had I chosen the best final submission, I’d ended up still 20 spots higher or so in the final tally (conveniently ignore the fact here that that’s likely true for a whole bunch of people).
Similarly, when browsing the forum explaining the top teams submissions, I realised all those simple things that I just didn’t think of that would have improved my model even more. Clinging to this type of what ifs won’t yield anything productive, but is all too easy.

A more constructive path is to practice mindfulness and try to let go of any regrets. Once it’s all said and done and there’s nothing you can change, you are better off instead focusing on learning as much as possible from all the great minds sharing their insights and strategies in the forum after the competition ends.
What is next for me then? To keep it simple, I will end this post the way it started, with an inspirational quote since there is always someone who already have said it better than you ever would be able to. This time one of my all time favourite quotes from the old fox Samuel Becket;
Try again. Fail again. Fail better.
I Found 10,000 Ways That Didn’t Work was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.