Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
I walked into the office at 7 am only to find two of my (usually laid-back) colleagues in panic. Our cloud service had crashed and became inaccessible to all our users — what a lovely wake-up. So what can you do when something like this happens, and you literally need time to stop?
I work as a developer at Kentico Cloud, a Content as a Service system. Over the last few years, we have continued to add to our catalog of enterprise features. We introduced one feature in particular that we knew would make our product top notch — a Content Management API. This API allows users to import existing content into the content management system (CMS) rather than having to insert it manually through the web interface. After we finally got it out, there was tremendous relief among developers, but we couldn’t foresee what happened next. That is where the journey starts for one of our customers, who in the end inadvertently helped us — let’s call him Adam.
Adam is responsible for his company’s website, and he is working hard against a tight deadline. Before his website can go live, he needs to migrate a massive amount of content from their old CMS to Kentico Cloud. It would take weeks to copy-paste everything manually. Knowing that we will be releasing a new Content Management API close to his deadline, he eagerly awaits the feature and carefully prepares his import scripts.
Not even a week after the release he executes the first batch of his import data set. A few minutes later, Kentico Cloud’s administration interface is unresponsive, struggling with serving the incoming request, and moments after, it shuts down; which brings me back to the intro and my two freaked out colleagues. When you have a responsibility for a cloud service that serves thousands of clients, this is a major bummer. Thankfully, this issue affected only the management part of the CMS; therefore, clients’ websites depending on the data delivery from the cloud unaffected.
By the time I arrived at work, my colleagues had figured out that it was Adam who executed probably the first unintentional DoS attack against our servers. But the primary goal of that morning was clear — make sure that the management part of our service is up and running as soon as possible.
First Ensure the Service Is Working, Then Investigate
After the first analysis of logs, it was clear that the import batch from Adam had caused the failure. The logic processing these requests exhausted all available physical memory of our web service in Azure. In the meantime, our Customer Support had already been in touch with Adam and learned about his issue. So on the one hand, we had an enterprise customer with a tight deadline and a failing import, and on the other, all other customers were left with a broken app.
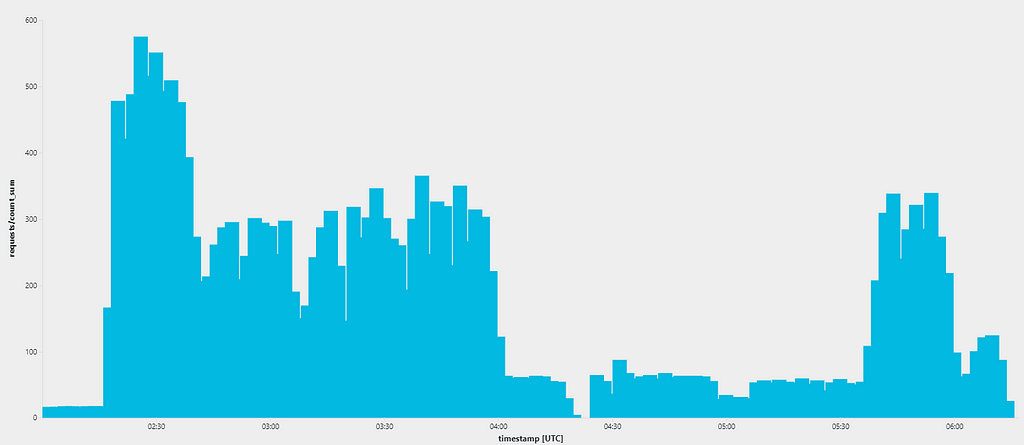 Number of parallel requests during the DoS attack
Number of parallel requests during the DoS attack
We acted quickly. First, we created a memory dump for later investigation. Then, as a quick fix, we aimed to isolate Adam from others by spinning out a new instance of the web service in Azure just for his project and reconfigured our CDN to redirect all his requests there. Within a few hours of the first incident, we were able to resume the service for all our clients as well as enable Adam to finish his import in time. Thanks to this fix, the speed of API requests increased as he was granted a dedicated architecture for the time being.
How Could This Happen?
The fix bought us some time, but we knew we needed to find a lasting solution as there could be another customer preparing to do the very same thing as Adam. At this point, we still had no clue how a single customer could exhaust all the server memory. However, we had the memory dump and Adam, who had been very helpful. He provided us with the import scripts and explained the actions he took before the server stopped responding.
We found out that the content items of Adam’s project were duplicated in the server memory so many times that they caused the memory exhaustion. At first sight, it was not apparent what had caused it. But it’s always fun to debug, especially when you are not under time pressure, right? We realized there were multiple interconnected problems.
Azure Tables and Caching
First of them were the Azure Tables. We used them as storage for all content items, and as they are just simple key-value storage, they do not really support regular querying nor ordering. Therefore, to sort or filter content items of a specific project, we first had to load all of them into memory and do these operations there. Right, but that does not explain why there were so many duplicates of content items in the memory.
A long time ago when we were implementing caching, we decided it was a good idea to clone each item before returning it from the repository. That should have ensured that no one could mutate its actual value in the cache. It was a valid theory, but not a particularly scalable one. When Adam imported his content items, the service needed to perform validation checks for every one of them to ensure all the links were valid. As his items were linking to each other heavily, these checks were repeatedly creating snapshots of all the content items. Do you see how the memory consumption exponentially grew up? Now multiply that by the number of parallel requests.
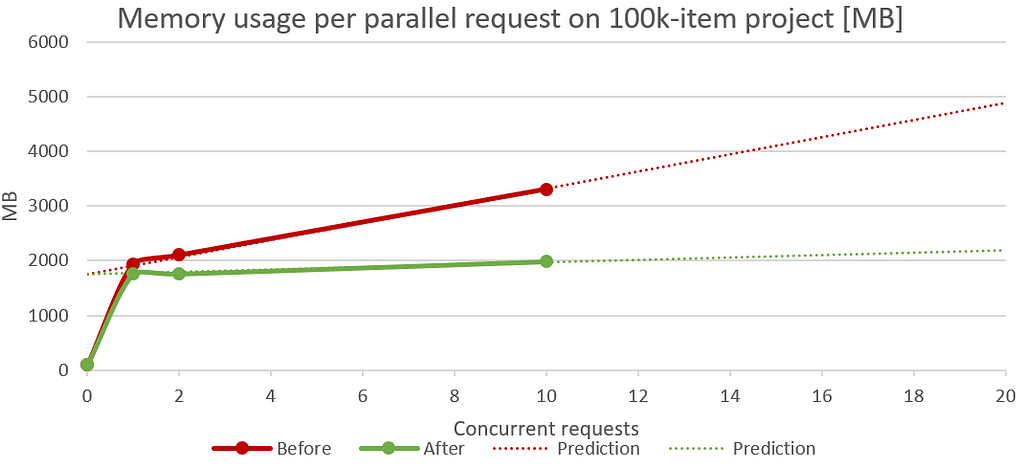 This is not your average graph… this one is better flat!
This is not your average graph… this one is better flat!
Implementing a Future-Proof Solution
After we connected all the pieces of the puzzle, we started addressing the issues. We identified two main technical debts:
- All content items were being cloned before we returned them from the repository
- Relationships between items were computed ad-hoc — there were no inverted indexes
Once we knew what the problem was, solving the first issue was a piece of cake. We simply introduced a read-only interface of the returned item from the repository. This adjustment did not require any significant changes within the system. If a module needed to mutate a returned item, it would do so locally.
To tackle the second technical debt, we had to introduce an inverted-index search. Instead of crawling all the content items to find out where a particular item was used, we only had to look up its usages in the inverted-index which contained all the parent-child relationships. It is the very same thing Google does when you search for ‘Apple’. Their algorithm does not search through the whole Internet when you press the search button — that would take ages; instead, it looks up the results in an existing index.
These two changes were not proper solutions to our problems, but rather quick patches. We still had to load all the project content items into the memory for our service to work correctly. However, we were able to address the issues in negligible time and prevent similar incidents from happening in the near future.
Even though the current problem was resolved, we were determined to come up with a long-term vision. These quickly addressed technical debts gave us more time to research and prepare for significant changes in our architecture. With many enterprise clients, we aimed to be prepared to fulfill their future requirements and needs. We engaged in discussions about changing the underlying database service and adjusting the whole service layer to optimize memory consumption further. That would give us a service that scales way better, ensuring great response times without the need to spin up dedicated servers for every other customer.
The Main Takeaway
We have learned our lesson about product scaling and were reminded that losing focus on core architecture implementation brings serious consequences to our ability to provide an always-on service. Thanks to Adam, we now know just how important it is to take a step back and look at our architecture and identify possible bottlenecks before introducing new features to our customers. Plus, we also learned that taking a customer-first approach is crucial at all times. With great customer care, we were able to convert many of them into partners helping us to improve the product.
If you’d like to find out more about Kentico Cloud, visit our homepage, it’s always on!
The Day a Client Helped Us by DoS-ing Our Cloud Service was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.