Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Photo by Anastasia Dulgier on Unsplash
Photo by Anastasia Dulgier on Unsplash
I already talked about networks a few times in this blog. In particular, I had this approach to explain spatial segregation in a city or to solve the Guess Who? problem. However, one of the questions is how to generate a good network. Indeed, I aim to study strategy to split a network, but I need first to work with a realistic neural network. I could have downloaded data of a network, but I’d rather study the different models proposed to generate neural networks.
I will explain and generate the three most famous models of neural networks:- The Erdős-Rényi model;- The Watts and Strotgatz model (small world model); - The Barabási-Albert preferential attachment model.
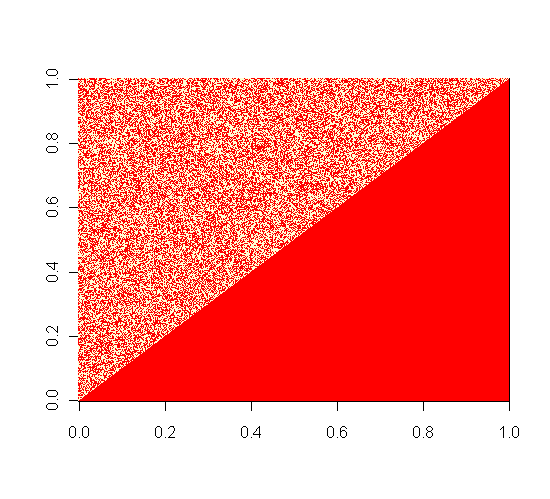
We represent each model with a matrix of acquaintance. The intersection of the column i and the row j is a 1 if and only if the nodes i and the node j know each other. Since we simulate reciprocal neural network (i.e. if i knows j then j knows i), we can work on a triangle matrix and not worry about the lower triangle of our matrices. Here, I use the R function image() to represent these matrices. In red are the 0, in white are the 1.
The Erdős-Rényi model.
This model is certainly the simplest of the three models. Only two parameters are required to compute this model. N is the number of nodes we consider and p, is the probability for every couple of nodes to be linked by an edge.
This model assumes that the existence of a link between two nodes is independent to the other link of the graph. According to Daniel A Spielman, this model has not been created to represent any realistic graph. However, this model has some very interesting properties. The average path is of length log(N) which is relatively short.
Besides, if p < 1, for N great enough, the clustering coefficient converges toward 0 (almost surely). The clustering coefficient for one point, is in simple word the ratio between all the existing edges between the neighbors of this point to all the possible edges of these neighbors.
On this figure the clustering coefficient of A is 1/3, there are 3 possible edges between the neighbors of A (X-Y, Y-Z, Z-X) and only one (Z-Y) is linked.
The Watts and Strotgatz model (small world model).
This model is really interesting, it assumes that you know a certain number of persons (k) and that your are more likely to know your closest neighbors. The algorithm though more complicated than the Erdős-Rényi model’s is simple. We have 3 parameters. The number of the population (N), the number of close neighbors (k) and a probability p. For any variable, for every close neighbor, the probability to be linked with it is (1-p). For every close neighbor not linked with, we choose randomly in the further neighbors the other link.
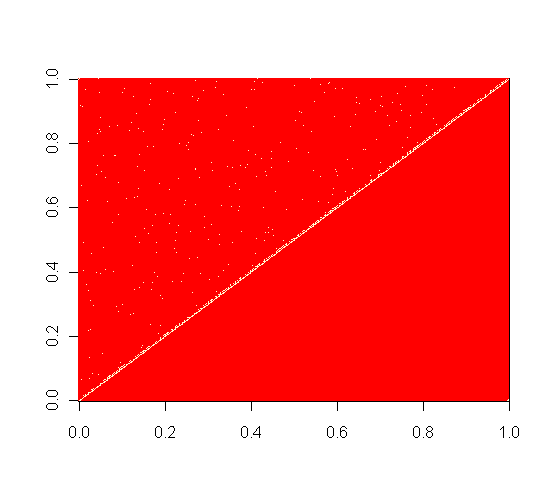
Because this model generates some conglomerates of people knowing each other, it is really easy to be linked indirectly (and with a very few number of steps) with anyone in the map. This is why we call this kind of model a small world model. This is, in the three we describe here the closest from the realistic social network of friendship.
The Barabási-Albert preferential attachment.
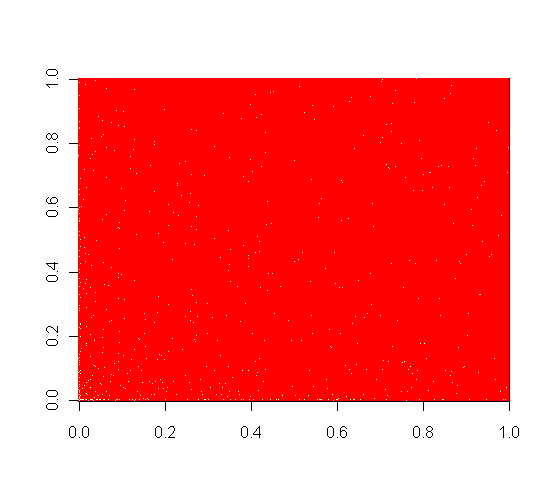
This model is computing with a recursive algorithm. Two parameters are needed, the initial number of nodes (n0) and the total number of node (N). At the beginning, every initial node (the n0 first nodes) knows the other ones, then, we create, one by one the other node. At the creation of a new node, this node is linked randomly to an already existing node. The probability that the new node is linked to a certain node is proportional to the number of edges this node already has. In other word, the more links you have, the more likely new nodes will be linked to you.
This model is really interesting, it is the model for any neural network respecting the idea of “rich get richer”. The more friends one node has, the more likely the new nodes will be friend with him. This kind of model is relevant for internet network. Indeed, the more famous is the website, the more likely this website will be known by other websites. For example, Google is very likely to be connected with many websites, while it is very unlikely that my little and not known blog is connected to many websites.
The code (R) :
# ER model
generateER = function(n = 100, p = 0.5){ map = diag(rep(1, n)) link = rbinom(n*(n-1)/2, 1,p) t = 1 for(j in 2:n){ for(i in 1:(j-1)){ map[i,j] = link[t] t = t + 1 } } return(map)}# WS modelf = function(j, mat){ return(c(mat[1:j, j], mat[j,(j+1):length(mat[1,])]))}g = function(j, mat){ k = length(mat[1,]) a = matrix(0, nrow = 2, ncol = k) if(j>1){ for(i in 1:(j-1)){ a[1,i] = i a[2,i] = j } } if(j<k){ for(i in (j+1):k){ a[1,i] = j a[2,i] = i } } a = a[,-j] return(a)}g(1, map)callDiag = function(j, mat){ return(c(diag(mat[g(j,mat)[1, 1:(length(mat[1,])-1)], g(j,mat)[2, 1:(length(mat[1,])-1)]])))}which(callDiag(4,matrix(runif(20*20),20,20)) <0.1)
generateWS = function(n = 100, k = 4 , p = 0.5){ map = matrix(0,n,n) down = floor(k/2) up = ceiling(k/2) for(j in 1:n){ map[(((j-down):(j+up))%%n)[-(down + 1)],j] = 1 } map = map|t(map)*1 for(j in 2:n){ list1 = which(map[(((j-down):(j))%%n),j]==1) listBusy = which(map[(((j-down):(j))%%n),j]==1) for(i in 1:(j-1)){ if((j-i<=floor(k/2))|(j-i>= n-1-up)){ if(rbinom(1,1,p)){ map[i,j] = 0 samp = sample(which(callDiag(j, map) == 0), 1) map[g(j, map)[1, samp], g(j, map)[2, samp]] = 1 } } } } return(map*1)}# BA model
generateBA = function(n = 100, n0 = 2){ mat = matrix(0, nrow= n, ncol = n) for(i in 1:n0){ for(j in 1:n0){ if(i != j){ mat[i,j] = 1 mat[j,i] = 1 } } } for(i in n0:n){ list = c() for(k in 1:(i-1)){ list = c(list, sum(mat[,k])) } link = sample(c(1:(i-1)), size = 1, prob = list) mat[link,i] = 1 mat[i,link] = 1 } return(mat)}# Graphs
image(generateER(500))image(generateWS(500))image(generateBA(500))
Random generation of network models in R was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.