Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Folks!
Today I am going to talk about a topic which took me a long time(reaallyy long time) to understand, both the motivation of usage as well as its working-Connectionist Temporal Classification(CTC).
Before talking about CTC, let us first understand what Sequence-to-Sequence models are :-)
Sequence-to-Sequence Models: These are neural networks which takes in any sequence — characters, words, image pixels and gives an output sequence which could be in the same domain or a different one as the input.
Few examples of Sequence to Sequence models:
- Language translation problem — where input is a sequence of words(a sentence) in one language and output is another sequence of words in a different language.
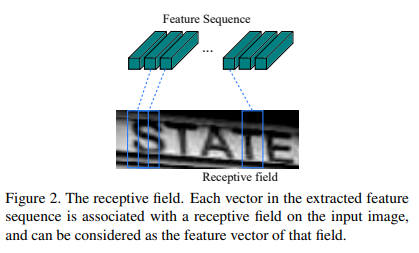
- Word Recognition problem — where input is an image containing only a word which is then converted into a sequence of feature vectors (feature map’s columns acting as time dimension here) and output is a sequence of characters present in the word image.
- Speech-to-text problem — where input is the audio sequence and output is a sequence of phonemes.
Recurrent neural networks are generally used for such sequence to sequence problems since the network has to take into account not just the current input but also inputs before and after in order to make predictions.
Now what does Sequence-to-Sequence models have anything to do with Connectionist Temporal Classification(CTC)? Well, CTC is an algorithm used to tackle a key issue faced when training seq-2-seq models, which is, when the length of the input and output sequences do not match.
Let me dive deep into a problem I have worked on before to uncover the details of CTC :-)
Word Recognition: The problem is to predict the word present in an image. One way to solve this is by treating it as a sequence-to-sequence problem and using a hybrid architecture of Convolutional and Recurrent Neural Nets. The architecture of CRNN is as follows:
 An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition - Baoguang Shi et al.
An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition - Baoguang Shi et al.
Here, the input sequence is the convolutional feature map and the output will be a character sequence.
To give more idea behind what exactly is happening, let me explain the flow:
- Conv Net takes in an input word image, say of size WxHx3 and produces a convolutional feature volume, say of size W/2 x H/2 x D, where D is the depth of the feature volume.
- Now every column of size 1 x H/2 x D is fed as an input (note that there are W/2 such columns) to the RNN which in turn produces a character from the vocabulary set as the output.
- So the CRNN is trying to predict characters present in every column of a feature map. Note that a column may or may not contain a character and that is why there is one more output label used — blank ‘-’ (check the output of above image).
 Baoguang Shi et al.
Baoguang Shi et al.
One can ask what could be the temporal dependency here in case of images. Well since the feature maps are split and the predictions are made for every column, it is highly unlikely that one complete character will fall inside a single column. Hence a character’s pattern learning depends not only on the current column but also on columns before and after it.
Let’s take a look at the output from RNN to make things clear.
 1. input image
1. input image 2. predicted sequence from RNN
2. predicted sequence from RNN 3. decoded output
3. decoded output
Note that the decoded output(3) is formed by collapsing repeated characters and removing blank character(if any) from the predicted sequence(2) coming out of RNN.
For clarity, let me define few things beforehand:
a. input_sequence: the input sequence of length W/2 which is fed to RNN.
b. predicted_sequence: the predicted output sequence of length W/2 which is the output from RNN.
c. target_sequence: the ground-truth output sequence of length W/2.
d. decoded_sequence: the decoded output sequence of length ≤ W/2.
While training such a network, all we have is <1. input image, 3. decoded output> pair as a training instance. But the neural net gives out predicted_sequence as output whose length is not equal to that of the decoded output.
predicted_sequence of length W/2 cannot be compared with decoded_sequence of length ≤ W/2 while computing loss.
- Note: We assume that the input and predicted sequences are synchronous. i.e. the order will be the same.
Problem: So inorder to train this net, we need to know what the target_sequence is. But how are we going to get that target_sequence? We certainly cannot annotate every timestep in the sequence of length W/2(that’s impossible!).
Solution: Guess the target_sequence using a reasonable heuristic. Yes you read it right. Make an initial guess for the target_sequence. Consider the input image above, what is the decoded output for that input?
decoded output →“STATE”
Say the length of the target_sequence/predicted_sequence(i.e output from the RNN) is 14. Now let’s guess the target_sequence to be “SSSTTAAAATTEEE” (we’ll look at blank character later).
Given that we have a target_sequence, we can train the network with that sequence for the first step, then use the network’s predictions as the new target_sequence(for next step) and iterate it over and over during training — Iterate and Estimate.
But there is one key problem here. How do we ensure that the network’s predicted target_sequence when decoded gives us the desired output, “STATE” in our case?
What if the RNN outputs “RRRRAAAEEELLLL”? We can’t use this output sequence as the new target_sequence for the next step in the training process. Hence we need to impose few restrictions on the sequence predicted by the RNN.
Constraint 1: Instead of taking into account the predictions of entire vocabulary(alphabets A to Z), consider only the alphabets that is part of the decoded output.
In our case, the alphabets S,T,A,E are part of the decoded output “STATE”.
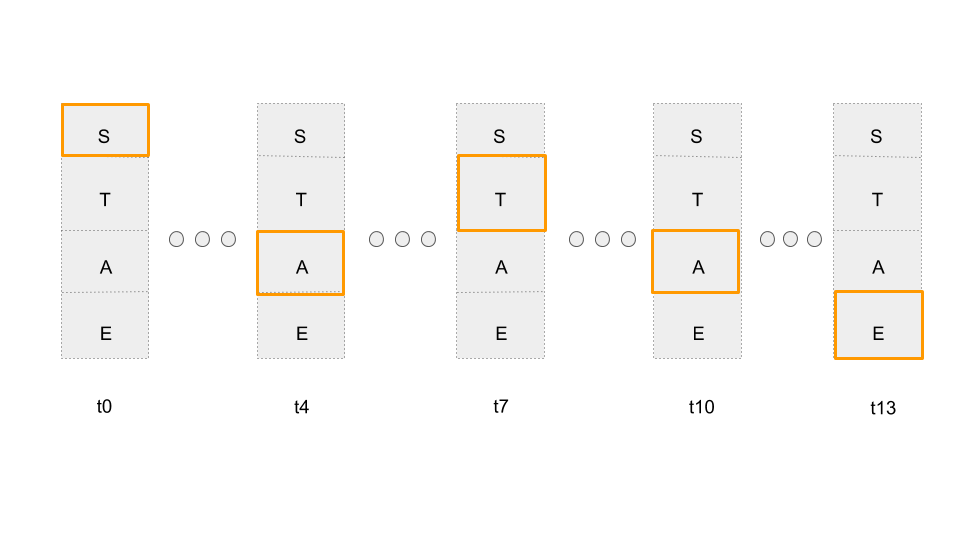 Considering only target alphabets. Most probable character for a given timestep is highlighted in orange. For example sake, I have highlighted only 5 steps(decoded output for this eg. is SATAE)
Considering only target alphabets. Most probable character for a given timestep is highlighted in orange. For example sake, I have highlighted only 5 steps(decoded output for this eg. is SATAE)
Okay, this now ensures that our network produces a predicted_sequence containing only the alphabets in the decoded output. But there is no constraint on the sequence in which the alphabets should be outputted.
For eg: the RNN outputs “SSAAAATTTAAEEE”, which still contains only the target alphabets but when decoded produces SATAE instead of STATE.
Constraint 2: To ensure the network outputs a sequence which when decoded gives us the desired collapsed output, let’s impose the following constraint:
Not only consider the alphabets S,T,A,E but also order the individual alphabets in the sequence in which they occur in the decoded output(even if the alphabets have to be repeated).
 Use Viterbi algorithm(dynamic programming) to compute the best path from a set of all possible paths starting from S ending with E.
Use Viterbi algorithm(dynamic programming) to compute the best path from a set of all possible paths starting from S ending with E.
And now fix that the first output should always be the top left symbol and last output should always be the bottom right symbol and the sequence should always be from top to bottom strictly i.e no upward movement. Every path from the top-left symbol to the bottom-right symbol is considered a valid sequence/alignment, since it will always decode to a valid ‘decoded_sequence’.
Visualize every output symbol at every timestep as a node in a graph and edges represented by arrows. Every node’s score is its probability from the network at that timestep and the edge scores are 1. The score of a sequence(or path) is the product of probabilities of all nodes contained in it.
Sub-Problem: Given a set of such valid sequences, find the most probable sequence?
Solution: This problem is solved using Viterbi’s algorithm(dynamic programming).
Once we ensure that the predicted sequence is a valid sequence(or alignment), we can use the ITERATE and ESTIMATE approach to train the network. One could also use a pretrained RNN trained on a similar task to make the training process more robust.
But all of this is heavily dependent on how the initial target sequence is guessed as well as how the target_sequence is computed during training(max probable sequence using Viterbi’s algorithm). As a result of which this approach is sub-optimal.
Instead of choosing the most probable sequence, we use an expectation over all the possible valid sequences. This again can be computed using dynamic programming and the algorithm used is known as CTC-Forward-Backward algorithm. I am not going to get into the details of Forward-Backward/Viterbi algorithm as it is still a grey area for me.
Lastly, consider the case when the output has repeated characters. Let the output word be “LETTER” and the predicted_sequence be “LLLLEETTTTEERR”. Now what happens when this predicted_sequence is collapsed?
We get the decoded output as “LETER” which is undesirable.
Therefore inorder to account for repetitive characters in the output domain, blank character(-) is included as part of the vocabulary. Basically a neural-net outputs a blank character when none of the symbols in the vocabulary is present at that timestep.
So instead of producing “LLLLEETTTTEERR”, an RNN with blank as part of the vocabulary might now output “-L-EE-TT-T-E-R” which when decoded produces “LETTER”.
Since a blank character has been included and it can happen to occur anywhere in the target_sequence, we arrange the target alphabets + blank as follows:
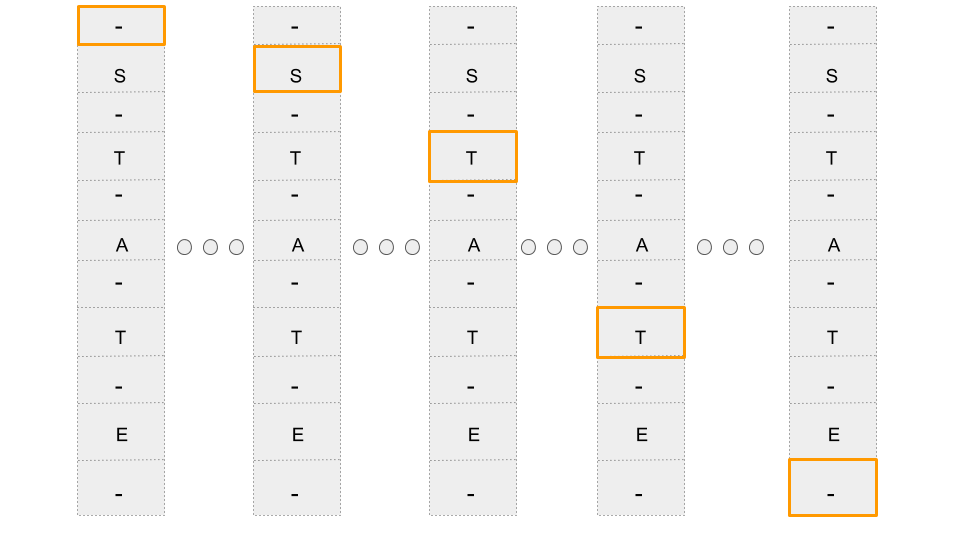 Blanks are inserted before and after every target alphabet. Note that only few timesteps are shown in the above diagram.
Blanks are inserted before and after every target alphabet. Note that only few timesteps are shown in the above diagram.
Now let me break down the term “Connectionist Temporal Classification” to see what it actually means?
Our solution can now label(or predict) every timestep in the sequence. This task of labelling unsegmented data sequences is called Temporal Classification and since we use RNNs to label this unsegmented data, it is known as Connectionist Temporal Classification[1].
[1] as mentioned in Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks — Graves et al.
To make it more clear, here the unsegmented data sequence is our decoded output, segmented data sequence will be the target_sequence and we use RNN to label it.
I hope you all got the intuition as to how neural networks are trained for such sequence to sequence problems where input and output sequence length do not match.
My blog post is inspired from this brilliant CMU lecture on CTC: https://www.youtube.com/watch?v=c86gfVGcvh4. Take a look at it!
Cheers :-)
Neural Networks Intuitions: 4. Connectionist Temporal Classification was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.